Neurona natural
Una neurona natural funciona como una función de integración espacio-sensorial que recibe estímulos externos de otra neurona a través de neurotransmisores. El impulso eléctrico se transmite a una velocidad de 30 m/s, bastante lenta en comparación con la que se puede conseguir en un circuito integrado.

El potencial de acción de una neurona comienza a un bajo nivel (umbral de estimulación) y aumenta al llegar un estímulo (pico de potencial de acción), después, se empieza a reducir (repolarización) hasta llegar a un nivel inferior que el inicial (hiperpolarización).
Neurona artificial
Se tratan de modelos que:
- Bioinspirados: las neuronas del cerebro son muy complejas
- Permite resolver problemas muy complejos que son muy difíciles de plantear algorítmicamente.
- Tiene la capacidad de aprender.
Neurona más simple

Modelo más sencillo de una neurona
- $x_i$: entrada de la neurona ($n$ entradas).
- $w_i$: peso de la entrada $x_i$.
- $y$: salida, que se calcula como una suma ponderada de las entradas:
Neurona binaria con umbral
Definida por McCulloc & Pitts en 1943 (ver introducción), donde añaden un valor umbral a la salida de la neurona:
$$ z = b + \sum_i x_i w_i $$Donde $b$ es el término independiente o bias. Después, sobre este resultado, se aplica una función paso Heaviside:
$$ y = \begin{cases} 1 \quad \text{si } z \ge 0 \\ 0 \quad \text{en otro caso} \\ \end{cases} $$Esta última función se le llama la función de activación.

Con esto, la neurona se activará cuando $z \ge 0$,
$$ b + \sum_i x_i w_i \ge 0 \implies \sum_i x_i w_i \ge -b $$Entonces, el umbral de activación $\theta = -b$.
Gracias a esto, ya es posible implementar ciertas funciones lógicas. Sin embargo, tiene un gran problema: la función paso no se derivable en todos los puntos. Esto es importante porque se necesita para los algoritmos de aprendizaje.
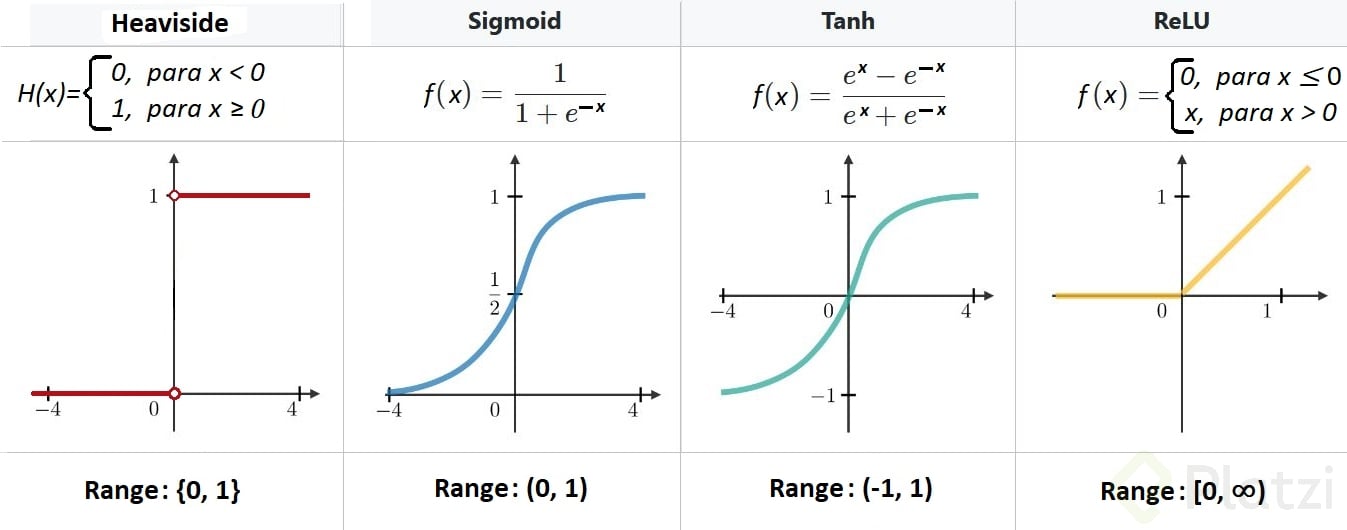
Otras funciones de activación
Una red neuronal artificial que use la función de activación identidad $f(x) = x$ es equivalente a una red monocapa.
Esto se debe a que el propósito de la función de activación es proporcionar cierta linealidad, porque de lo contrario, se puede colapsar todo a una única transformación lineal.
Para arreglar el problema de la derivada, solo se necesita cambiar la función de activación. Por ejemplo, una neurona lineal rectificada:
$$ y = \begin{cases} z \quad \text{si } z \ge 0 \\ 0 \quad \text{en otro caso} \\ \end{cases} $$O una neurona sigmoidal:
$$ y = \frac{1}{1 + e^{-z}} $$Este es el modelo de neurona más utilizado ya que es derivable en todos los puntos. Sin embargo, su principal inconveniente es que a veces la derivada es muy pequeña, lo que puede suponer un problema para el algoritmo del descenso del gradiente.
Representación común de una Neurona Artificial
Por tanto, una representación más general de una Neurona Artificial se puede ver en el diagrama de la figura.

Representación común de una Neurona Artificial
- $x_i$: señales de entrada
- $w_{ki}$: pesos de la sinapsis
- $b_k$: término independiente o bias
- $\sum$: función de suma
- $v_k$: resultado de la suma
- $\phi(\cdot)$: función de activación
- $y_k$: salida de la neurona
Todo esto para una neurona $k$.
También es posible representar el término independiente o bias como el peso $w_0$, que se corresponde con una variable de entrada $x_0 = 1$ que siempre es constante.
Red Neuronal Artificial
Una Red Neuronal Artificial (RNA) es una estructura compuesta por neuronas artificiales profusamente conectadas entre sí. Tiene la capacidad de aprender a partir de los datos de entrada mediante la modificación de sus pesos sinápticos.
Existen diferentes modelos o arquitecturas dependiendo del tipo de neurona y su organización.

Ejemplo de una RNA hacia delante
Aprendizaje automático
Consiste en una serie de regresores, algoritmos basados en fundamentos matemáticos («matemáticas que aprenden») con capacidad de aprender a resolver ciertos tipos de problemas.
Programa informático que aprende de la experiencia $E$ en relación a una tarea $T$, usando una medida de rendimiento $P$.
Si mejora sus prestaciones medidas por $P$ en la realización de $T$ a través de $E$, quiere decir que ha aprendido.
Ejemplos de uso cotidiano de sistemas basados en aprendizaje automático:
- Filtros para spam
- Reconocimiento y etiquetado de caras
- Asistentes virtuales para el hogar o el móvil
- Análitica de datos, de procesos, de opiniones, …
- Recomendadores de Amazon, Netflix…
- Clasificación de cartas en servicios postales
- Diagnóstico médico
- Traductores automáticos
- …
Estas estrategias tienen un gran protagonismo en el aprendizaje de la máquina:
- Hace viable el desarrollo de ciertas aplicaciones.
- Aborda una IA de propósito general a través del aprendizaje.
- La potencia de cálculo, capacidad de memoria, disponibilidad de los datos están permitiendo un desarrollo inédito de este campo.
Las diferentes estrategias normalmente se clasifican en las tres siguientes clases:
Aprendizaje supervisada: (aprender de ejemplos)
Durante la experiencia $E$ se indica cómo realizar $T$, dado que dispongo de los pares dato-salida deseada.
De este modo, a la hora de diseñar el sistema, es necesario encontrar los valores de los pesos que produzcan la salida deseada (minimice el error medido por $P$ respecto al valor deseado). Funciona a partir de ejemplos.
Se trata del método más utilizado.
Conjunto de entrenamiento: formado por pares dato-salida deseada, lo suficientemente representativos del problema a resolver (datos de calidad).
Ajuste de pesos: se entrena la RNA ajustando los pesos para que en la medida de lo posible la red responda con la salida deseada.
Estrategias que veremos:
- Perceptrón (redes monocapa)
- Regresión lineal y polinómica (predicción), y logística (clasificación)
- Retropropagación (redes multicapa)
Aprendizaje no supervisado: (clasificar)
Durante la experiencia $E$ no se indica cómo realizar $T$, pero se dispone de un criterio para poder realizar clasificaciones entre datos de entrenamiento lo suficientemente parecidos. Se maximizan las similitudes de los elementos de cada clasificación.
Se trata del segundo método más utilizado.
Estrategias que veremos:
Aprendizaje por refuerzo:
Se dan indicios si la realización de $T$ está bien o mal. Se fortalecen las decisiones correctas y se debilitan los caminos que dan lugar a decisiones incorrectas.
Además, se especifican criterios que permitan determinar de forma temprana decisiones erróneas. Se suelen usan en problemas donde la variable temporal es significativa (robótica).
Aprendizaje supervisado
Perceptrón
Un perceptrón es una RNA con una única capa de neuronas, cuya función de activación es normalmente una función paso. Al ser una única capa, todas las neuronas son y producen resultado independientes.
Se trata de un algoritmo de aprendizaje supervisado (a partir de ejemplos) de clasificación binaria lineal.
Se propuso a finales de los 50. En aquel momento, fue de las primeras aportaciones al campo del aprendizaje automático. Permitía la resolución de problemas partiendo de datos y sin necesidad de codificar exactamente la solución usando un algoritmo conocido.
Supongamos que tenemos un problema de clasificación en el que se debe discriminar entre 2 clases, cuyos elementos se representan con dos variables. Partimos de un conjunto de elementos del que ya conocemos su clasificación (conjunto de entrenamiento), y se desea que cuando se introduzcan unos nuevos, se determine a cuál pertenece.
Nótese que el funcionamiento del clasificador dependerá de la calidad de los datos iniciales: si no son representativos del problema, los resultados serán malos.
Para ello, se puede utilizar una neurona con 2 entradas (una por cada variable) y los pesos se ajustarán a través de un algoritmo de aprendizaje, que inicialmente se escogerán aleatoriamente. Se utilizará una función de activación signo.
Como resultado, esta neurona dividirá en dos clases el espacio de posibles entradas.
Algoritmo de convergencia del perceptrón
A partir del ejemplo anterior, solo queda diseñar un algoritmo que calcule los pesos de la neurona.
- $x(n)$: vector de entradas
- $w(n)$: vector de pesos
- $b$: bias
- $y(n)$: vector de salida del sistema
- $d(n)$: vector de salidas deseadas
- $n$: time step o iteración
- $\eta$: learning rate o coeficiente de aprendizaje
[Que sean vectores da igual, para los siguientes cálculos se pueden suponer valores escalares.]
Se trata de un valor en el intervalo (0, 1) (normalmente muy pequeño) que representa el cambio que se aplicará sobre el peso. Su función es limitar el aprendizaje de modo que los cambios en cada ciclo sean pequeños.
- Muy alto: creará un comportamiento oscilatorio y es posible que diverga en lugar de converger.
- Muy bajo: el entrenamiento será muy lento.
Los valores concretos dependen del problema, y se suele modificar manualmente mediante prueba y error.

Para el ejemplo, usaremos:
$$ y(n) = \operatorname{sign}( w^T(n) x(n) )$$Al multiplicar un vector horizontal por uno vertical, esencialmente se realiza una suma ponderada. $\operatorname{sign}$ se define como:
$$ \operatorname{sign}(x) = \begin{cases} 1 \quad& \text{si } x > 0 \\ 0 \quad& \text{si } x = 0 \\ -1 \quad& \text{si } x < 0 \\ \end{cases} $$Entonces, si $d(n)_i=1$ quiere decir que $x(n)_i$ pertenece a la primera clase, y si $d(n)_i=-1$ entonces $x(n)_i$ es de la segunda clase.
El siguiente valor de los pesos será:
$$ w(n+1) = w(n) + \eta[d(n) - y(n)]x(n) $$Al peso actual $w(n)$ se le suma lo que falta por llegar a valor deseado ($d(n) - y(n)$), pero multiplicado por el learning rate y que el proceso sea iterativo (computar una integral).
Entrenamiento (calcular los pesos):
w[0] = random()
sign = lambda x: 1 if x > 0 else -1
for n in steps():
y[n] = sign(transpose(w[n]) * x[n])
w[n+1] = w[n] + learning_rate * (d[n] - y[n]) * x[n]
Evaluación:
y = sign(transpose(w) * x)
Explicación de su funcionamiento:
Si $y(n) = d(n)$
==> $w(n+1) = w(n)$
==> No hay cambios porque ya es el valor que queremos.Si $y(n) < d(n)$
==> Queremos que $w(n+1)$ aumente para hacer la salida más grande
==> $ \textcolor{red}{d(n)} - \textcolor{aqua}{y(n)} > 0 \implies \textcolor{red}{\eta} [\textcolor{red}{d(n) - y(n)}] \textcolor{red}{x(n)} > 0 \implies w(n+1) > w(n) $ (rojo positivo y azul negativo)Si $y(n) > d(n)$
==> Sucede lo mismo, solo que $w(n+1)$ disminuye.
Por tanto, si obtenemos la salida deseada, no hay cambios. Sino, se aumenta o se disminuye el peso para obtener el resultado deseado.
Si las clases son linealmente separables, finalizará cuando el error sea 0; de lo contrario, intentará llegar al error mínimo. Para llevar a ese punto, suelen ser necesarios muchos epochs.

Problema de regresión
Consiste en estimar las relaciones entre una variable dependiente y una o más variables independientes (también llamadas regresores o predictores).
Es decir, se trata de aprender la función que mejor representen lo datos de entrenamiento.
Esto se utiliza principalmente para predecir nuevos valores que sigan con la tendencia de los datos actuales.
Los elementos a tener en cuenta son:
- Los datos de actuales
- Función a seleccionar al modelo (más o menos complicadas: parábolas, polinomios…).
Regresión lineal
Como es un problema de regresión, se intentará encontrar una función hipótesis $h(x)$. Al ser lineal, se tratará de una recta, cuya ecuación es:
$$ h(x) = \theta_1 x + \theta_0 $$Por tanto, es necesario encontrar el valor en el origen $\theta_0$ y la pendiente $\theta_1$.
Como nos interesa que ambas funciones sean iguales («$h$ es un imitador de $y$»), esto se trata de un problema de minimización: encontrar los parámetros $\theta_0$ y $\theta_1$ de modo que la distancia con la salida deseada sea mínima.
Esta distancia se puede expresar como $|h(x) - y|$, que es equivalente (en los reales) a $\sqrt{\left( h(x) - y \right)^2}$. Nos llega con un valor positivo, por lo que se suele quitar la raíz, así es más eficiente de computar (calcular raíces cuadradas es lento). Y como tenemos un conjunto de datos, realizamos la media de todas esas distancias. Se ha añadido un 2 en el denominador es para que se cancele cuando derivemos.
Esta es la definición del error cuadrático medio, una función de error o función de coste. En esta expresión, $x^{(i)}$ es el $i$-ésimo dato de entrada, $y^{(i)}$ su salida que se desea y $m$ el número de ejemplos de entrenamiento.
El algoritmo iterativo para minimizar el valor de $J(\theta_0, \theta_1)$ es:
- Iniciar en un valor dado de $\theta_0$ y $\theta_1$
- Variar estos valores de forma que $J(\theta_0, \theta_1)$ disminuya
- Repetir hasta que se llegue a un mínimo (puede ser local)
El cambio de los parámetros viene dado por la siguiente expresión:
$$ \theta_j := \theta_j - \alpha \frac{\partial}{\partial \theta_j} J(\theta_0, \theta_1) $$Expandiendo un poco:
$$ \begin{align*} \frac{\partial}{\partial \theta_j} J(\theta_0, \theta_1) =& \frac{\partial}{\partial \theta_j} \left( \frac{1}{2m} \sum^m_{i=1} \left(h(x^{(i)}) - y^{(i)}\right)^2 \right) \newline =& \frac{1}{m} \sum^m_{i=1} \left(h(x^{(i)}) - y^{(i)}\right) \left( \frac{\partial}{\partial \theta_j} \left(h(x^{(i)}) - y^{(i)}\right) \right) \newline \end{align*} $$A cada parámetro $\theta_j$, se le resta una cantidad determinada por la derivada de la función de coste, pero limitado por un parámetro $\alpha$, el learning rate. Este método se conoce como el método del descenso del gradiente o método del descenso rápido.
En concreto para el caso lineal con $\theta_0$ y $\theta_1$:
$$ \begin{align*} j = 0:& \quad \frac{\partial}{\partial \theta_0} \left(\theta_0 + \theta_1 x^{(i)} - y^{(i)}\right) =& 1 + 0 - 0 =& 1 \newline j = 1:& \quad \frac{\partial}{\partial \theta_1} \left(\theta_0 + \theta_1 x^{(i)} - y^{(i)}\right) =& 0 + x^{(i)} - 0 =& x^{(i)} \newline \end{align*} $$Por tanto, el gradiente es:
$$ \begin{align*} \frac{\partial}{\partial \theta_0} J(\theta_0, \theta_1) =& \frac{1}{m} \sum^m_{i=1} \left(h(x^{(i)}) - y^{(i)}\right) \newline \frac{\partial}{\partial \theta_1} J(\theta_0, \theta_1) =& \frac{1}{m} \sum^m_{i=1} \left(h(x^{(i)}) - y^{(i)}\right) x^{(i)} \newline \end{align*} $$Algunas consideraciones
Los cálculos anteriores sirven también para varias variables de entrada, simplemente $x^{(i)}$ es ahora un vector, y por tanto, $x$ es una matriz $n \times m$.
- $n$: número de características o variables de entrada
- $m$: número de ejemplos de entrenamiento
- $x^{(i)}$: vector de características para el ejemplo $i$ (filas)
- $x_j^{(i)}$: es la característica $j$ para el ejemplo $i$ (columnas)
Y la función de hipótesis tiene esta pinta (hiperplano):
$$ h(X) = \sum^n_{k=0} \theta_k x_k = \theta^T X$$Donde $x_0=1$ por conveniencia.
La función hipótesis $h$ puede tener multitud de mínimos locales en los que el algoritmo de minimización puede quedarse estancado y no encontrar una solución mejor.
Es importante que los datos estén en el mismo rango, dado que nuestra función de coste es una distancia entre ellos. Se puede solucionar normalizando:
$$ x_j^{(i)} = \frac{x_j^{(i)} - \mu_j}{s_j}$$Donde $\mu_j$ es el valor medio y $s_j$ es la desviación estándar.
$$ \mu_j = \frac{1}{m} \sum^m_{i=1} x_j^{(i)} $$ $$ s_j = \sqrt{\frac{1}{m} \sum^m_{i=1}\left(x_j^{(i)} - \mu_j \right)^2} $$
Regresión polinómica
Una recta no siempre sirve para aproximar funciones, a veces es necesario utilizar funciones de un orden mayor. En estos casos, se utiliza una función de hipótesis $h_\theta(x)$ polinómica. El proceso de entrenamiento es el mismo.
$$ h_\theta(x) = \theta_0 + \theta_1 x + \theta_2 x^2 + \ldots + \theta_n x^n$$Las variables que tengan valores preponderantes tendrán grados más altos, mientras que aquellas más insignificantes, serán más pequeñas.
Ajuste
Sin embargo, ¿qué grado se debe escoger?
- Underfitted: el grado es demasiado pequeño y el modelo tiene un mal ajuste a los datos. No es capaz de obtener la tendencia general.
- Mejor ajuste o Robusto: grado apropiado que sigue la tendencia general de los datos.
- Overfitted o Sobreaprendizaje: el modelo es demasiado complejo para el problema y la distribución de los datos. Tanto, que empieza a ajustarse a los datos del conjunto de entrenamiento y no a la tendencia general de los mismos.

Tipos de ajustes
¿Cómo se detecta y se diferencian los casos? Pues principalmente con experiencia y utilizando un conjunto de entrenamiento y otro de pruebas.
- Durante el entrenamiento, cuando la tasa de error del conjunto de entrenamiento se vuelve mínima, pero cuando se evalúa con los datos de prueba el error es mucho mayor, quiere decir que estamos en una situación de sobreaprendizaje.
- Cuando la tasa de error es muy alta y/o no converge, incluso tras muchas iteraciones del algoritmo, puede que estemos en una situación de underfitting.
Ajustando el grado del sistema arregla estos problemas.
Regularización
Encontrar el grado mediante prueba y error puede ser muy costoso, sobre todo cuando se trabaja con modelos y conjuntos de datos grandes.
Sin embargo, para intentar eliminar coeficientes superfluos y que complican el problema, se puede cambiar la función de coste de forma valores de $\theta_j$ estén ponderados por $\lambda \gt\gt$ (muy grande).
$$ J(\theta) = \frac{1}{2m} \sum^m_{i=1} \left[ \left( h_\theta(x^{(i)}) - y^{(i)} \right)^2 \textcolor{red}{+ \lambda \sum^m_{j=1} \theta_j^2} \right] $$De esta forma, si los parámetros no son clave para la minimización, se reducirán los $\theta$ de forma significativa haciendo que tiendan a 0.
Cálculo analítico
Hay ciertos casos donde se puede saltar el proceso de entrenamiento y calcular directamente los valores de forma analítica:
$$ \theta = (X^T X)^{-1} X^T y$$Siempre y cuando la matriz de características sea invertible, lo que puede pasar si tenemos muchas variables pero pocos datos.
| Descenso de gradiente | Ecuación normal |
|---|---|
| Necesidad de definir $\alpha$ | No es necesario definir $\alpha$ |
| Se recomienda escalar/normalizar | No es necesario normalizar |
| Muchas interaciones | Sin iteraciones |
| $O(kn^2)$ | $O(n^3)$ de calcular $(X^TX)^{-1}$ |
| Funciona bien para $n$ grande | Lento para $n$ grande |
| No tiene este problema | A veces $(X^TX)^{-1}$ no existe |
| - | No es aplicable a otros algoritmos |
Problema de clasificación
La tasa de error o medida de rendimiento describe cómo el modelo creado se ajusta a los resultados deseados. Su valor óptimo depende del problema: por ejemplo, cuando se quiere detectar células cancerígenas, mejor tener muchos falsos positivos que falsos negativos.
Aunque, si hay muchos falsos positivos, tampoco tiene mucha utilidad (efecto psicológico).
Este es un aspecto muy importante a tener en cuenta en los problemas de clasificación.
Si el sistema no es capaz de aprender de los datos y extraer el mejor umbral, es posible que se necesiten otras variables o que sobre algunas que no son relevantes.
Regresión logística
Es posible utilizar los métodos anteriores para discriminar entre elementos de varias clases. Una posible opción es fijar un valor umbral o fronteras de decisión a $h_\theta(x)$ que determine dónde termina una clase y comienza la siguiente.
$$ \begin{align*} h_\theta(x) \ge 0.5 \implies& \text{clase A} \\ h_\theta(x) \lt 0.5 \implies& \text{clase B} \\ \end{align*} $$
Nótese que para ello, es necesario aumentar una dimensión: el resultado de la clasificación.
Sin embargo, hay que considerar varios inconvenientes:
- $h_\theta(x)$ no está acotado de partida entre 0 y 1
- En general, la aproximación lineal no es un buen clasificador
Entonces, se suele usar una función sigmoide o función logística, que nos permite utilizar un umbral con más precisión.
$$ h_\theta(x) = \frac{1}{1 + e^{-\theta^TX}} $$
Función logística o sigmoide
Otra posible interpretación es considerar $h_\theta(x)$ como una «estimación» de la probabilidad de que $h_\theta(x)=0$ ante una entrada $x$ dada para una clase, o $h_\theta(x)=1$ para la otra.
Para tratar el problema de que ambas clases no sean linealmente separables, añadimos más grados a la expresión, igual que en la regresión polinómica. Por ejemplo, con dos variables de entrada:
$$ h_\theta(x) = g(\theta_0 + \theta_1 x_1 + \theta_2 x_1^2 + \theta_3 x_2 \theta_4 x_2^2) $$De igual forma, podemos aprender funciones como antes y obtener un umbral:
$$ x_1^2 + x_2^2 \ge 1 $$la ecuación de un círculo de radio 1.

Los círculos rojos es la predicción $h_\theta(x)=1$, mientras que $h_\theta(x)=0$ son las cruces verdes.
Cálculo de los valores de $\theta$
Igual que antes, utilizaremos como función de coste el error cuadrático medio, que nos dice la discrepancia entre los resultados obtenidos y los deseados. También la utilizamos para guiar el proceso de entrenamiento.
$$ J(\theta) = \frac{1}{2m} \sum^m_{i=1} \left( h(x^{(i)}) - y^{(i)} \right)^2 $$Dónde $h_\theta$ es la función sigmoide que hemos visto antes.
$$ h_\theta(X) = \frac{1}{1 + e^{-\theta^T X}} $$También se pueden utilizar otras funciones, como puede ser:
$$ k_\theta(x) = \begin{cases} -\log \left( h_\theta(x) \right) \quad& \text{si } y=0 \\ -\log \left( 1 - h_\theta(x) \right) \quad& \text{si } y=1 \\ \end{cases} $$Que se puede poner en una única expresión como:
$$ k_\theta(x, y) = - y \log(h_\theta(x)) + (1 - y) \log(1 - h_\theta(x)) $$Por tanto, se puede definir una nueva función de coste:
$$ \begin{align*} J(\theta) =& \frac{1}{m} \sum^m_{i=1} \left[ k_\theta\left(x^{(i)}, y^{(i)}\right) \right] \\ =& -\frac{1}{m} \sum^m_{i=1} \left[ y^{(i)} \log(h_\theta(x^{(i)})) + (1 - y^{(i)}) \log(1 - h_\theta(x^{(i)})) \right] \\ \end{align*} $$Esta función en concreto crece exponencialmente cuando hay mucha discrepancia (el argumento del logaritmo está entre 0 y 1, por tanto crece mucho).
Ahora, se para aplicar el método del descenso del gradiente, tras derivar, obtenemos que el ajuste de parámetros es:
$$ \theta_j := \theta_j - \frac{\alpha}{m} \sum^m_{i=1} \left[ \left( h_\theta(x^{(i)}) - y^{(i)} \right) x^{(i)}\right] $$¡Que es justo lo que teníamos antes en el caso lineal!, pero con:
$$ h_\theta(X) = \frac{1}{1 + e^{-\theta^TX}} $$Clasificación multiclase
Para fabricar un clasificador que diferente entre varias clases, lo único que hay que hacer es combinar varios regresores. Se diseña uno para cada clase vs el resto de clases; entonces, si tengo $n$ clases, necesitaré $n$ regresores.
Luego, para decidir entre ellos, se selecciona el valor máximo.

Retropropagación
La retropropagación o backpropagation es un algoritmo que se asocial al aprendizaje supervisado y computación neuronal. Hasta ahora hemos visto estructuras monocapa, pero este método permite redes multicapa para resolver muchos otros problemas.
| $x_1$ | $x_2$ | $y_{\text{acarreo}}$ | $y_{\text{suma}}$ |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 0 |

Puede verse que $y_{\text{acarreo}}$ se trata de una operación AND lógica, que es linealmente tratable. Por otro lado, $y_{\text{suma}}$ es la tabla de la verdad de una operación XOR, que no lo es, pero se puede resolver con una red de dos capas.
Las redes neuronales utilizadas para el reconocimiento de patrones, análisis de textos, etc; usan la retropropagación para entrenar redes de millones de neuronas, parámetros y múltiples capas, lo que se conoce como deep learning o aprendizaje profundo.
El problema de esta estrategia es que no se puede extraer el conocimiento de la red y ver cuál fue el factor decisivo. Este está diluido entre los pesos de cada una de las conexiones de las neuronas, donde cada uno, a priori, no tiene un significado asociado. Son modelos de cajas negras.
Ajuste de pesos
Se sigue el mismo criterio que siempre: ajustar iterativamente los pesos de cada neurona (limitado por el learning rate) para minimizar una función de coste.
$$ \Delta w_i = - \eta \frac{\partial\text{Error}}{\partial w_i} $$Se usa la regla delta para determinar el ajuste de cada peso en todas las capas. Nótese que al intentar reducir el error cometido, se debe usar la derivada negativa.
A continuación vamos a seguir un proceso iterativo, empezando desde el caso más simple hasta el más complejo, para entender bien cada paso.
Para el caso de una única neurona simple (sin función de activación):
- La salida de la neurona con $I$ entradas: $\displaystyle y = \sum^I_{i=1} w_i x_i $
- El error cometido: $E = (t - y)^2$, donde $t$ es la salida deseada
Según estas definiciones, el error depende de $y$ e $y$ depende de $w_i$, por lo que podemos expandir la derivada de la siguiente forma:
$$ \frac{\partial E}{\partial w_i} = \frac{\partial y}{\partial w_i} \frac{\partial E}{\partial y} $$Lo que es igual a:
$$ = x_i \left( 2 (t - y) (-1) \right) = - 2 x_i (t - y) $$Por tanto, el cambio en cada parámetro es:
$$ w_i^{(t+1)} = w_i^{(t)} + 2 \eta (t - y) x_i $$Curiosamente es la misma expresión que se utilizaba en el algoritmo del perceptrón. Si se sigue esta ecuación para el ajuste de los pesos de forma iterativa, convergirá para reproducir las salidas con bastante fidelidad a los datos reales.
Pero esto funciona solo para un único punto: al tener un conjunto de datos con $N$ puntos, se usaría las versiones adaptadas (que se resuelven de la misma forma):
$$ E = \frac{1}{2N} \sum^N_{n=1} \left( t^{(i)} - y^{(i)} \right)^2 $$ $$ \begin{align} \frac{\partial E}{\partial w_i} =& \frac{\partial}{\partial w_i} \left( \frac{1}{2N} \sum^N_{n=1} \left( t^{(i)} - y^{(i)} \right)^2 \right) \\ =& \frac{1}{2N} \sum^N_{n=1} \frac{\partial y^{(n)}}{\partial w_i} \frac{\partial \left[ (t^{(n)} - y^{(n)})^2 \right]}{\partial y^{(n)}} \\ =& \frac{1}{2N} \sum^N_{n=1} \frac{\partial y^{(n)}}{\partial w_i} \left[ 2 (t^{(n)} - y^{(n)}) (-1) \right] \\ =& -\frac{1}{N} \sum^N_{n=1} (t^{(n)} - y^{(n)}) x^{(n)}_i \\ \end{align} $$ $$ \implies w_i^{(n+1)} = w_i^{(n)} + \frac{\eta}{N} \sum^N_{n=1} (t^{(n)} - y^{(n)}) x^{(n)}_i $$(1) Primero se expande a la definición del error, (2) luego aplicamos el «truco» de descomponer la derivada, pero solo dentro del sumatorio, lo que nos ahorrará problemas luego. A continuación (3,4) resolvemos las derivadas de igual forma que se hizo antes y se simplifica un poco.
El caso anterior es para una neurona simple, pero nos falta por añadir una función de activación. Para este ejemplo, usaremos la función sigmoide:
$$ z = \sum^I_{i=1} w_i x_i \hspace{1cm} y = \frac{1}{1 + e^{-z}} $$Sabiendo que:
$$ \frac{\partial y}{\partial w_i} = \frac{\partial y}{\partial z} \frac{\partial z}{\partial w_i} \newline \frac{\partial y}{\partial z} = \frac{0 - (- e^{-z})}{(1 + e^{-z})^2} = \frac{1}{1 + e^{-z}} \frac{e^{-z}}{1 + e^{-z}} = y (1 - y) $$Volvemos a realizar la derivada, usando la misma estrategia de antes en descomponer las derivadas en función de sus diferentes dependencias:
$$ \begin{align} \Delta w_i =& - \eta \frac{\partial E}{\partial w_i} \\ =& - \eta \frac{1}{2N} \sum^N_{n=1} \frac{\partial y^{(n)}}{\partial w_i} \frac{\partial \left( t^{(n)} - y^{(n)} \right)^2 }{\partial y^{(n)}} \\ =& - \eta \frac{1}{2N} \sum^N_{n=1} \frac{\partial z^{(n)}}{\partial w_i} \frac{\partial y^{(n)}}{\partial z^{(n)}} \frac{\partial \left( t^{(n)} - y^{(n)} \right)^2 }{\partial y^{(n)}} \\ =& - \eta \frac{1}{2N} \sum^N_{n=1} \frac{\partial z^{(n)}}{\partial w_i} \frac{\partial y^{(n)}}{\partial z^{(n)}} (-2) \left( t^{(n)} - y^{(n)} \right) \\ =& - \eta \frac{1}{2N} \sum^N_{n=1} \frac{\partial z^{(n)}}{\partial w_i} \left( y^{(n)} (1 - y^{(n)}) \right) (-2) \left( t^{(n)} - y^{(n)} \right) \\ =& - \eta \frac{1}{2N} \sum^N_{n=1} x_i^{(n)} \left( y^{(n)} (1 - y^{(n)}) \right) (-2) \left( t^{(n)} - y^{(n)} \right) \\ =& \frac{2 \eta}{2N} \sum^N_{n=1} x_i^{(n)} y^{(n)} (1 - y^{(n)}) (t^{(n)} - y^{(n)}) \\ \end{align} $$(5) Partiendo de la definición de lo que queremos calcular, (6) se procede de forma análoga que antes, (7) pero también será necesario expandir la derivada de $y$ a la de $z$. (8, 9, 10) Finalmente se resuelven dichas derivadas y (11) se simplifica.
Aún no hemos terminado, ¡nos falta cómo retropropagar el error a las capas anteriores! En una RNA multicapa, las neuronas de las capas ocultas (las que producen las salidas intermedias) también afectan a la salida de la red, y por lo tanto a sus errores cometidos: también es necesario ajustar sus pesos.

Planteamiento del problema
Esto se puede generalizar a cualquier número de capas y neuronas por capa. Vamos a fijarnos en una única neurona de salida, la $k$-ésima, ya que una vez hecho el análisis, el resto se tratará de la misma forma. Nótese que este ya es el caso completo.
Definición de cada elemento:
- $x_{in}$ denota la entrada $i$ de la neurona $n$. Este valor lo calcula la neurona $i$, por lo que es lo mismo que escribir $y_i$.
- $w_{in}$ denota el peso $i$ que entra en la neurona $n$, asociado a la entrada $x_{in}$.
- $z_n$ es la función suma de la neurona $n$. Recordemos que estaba definida por la siguiente expresión, con $w_{0n}$ es el bias y $x_{0n}$ es siempre igual 1 por conveniencia. $$ z_n = \sum^N_{i=0} w_{in} x_{in}$$
- $f(z)$ es la función de activación genérica que se aplica sobre el resultado de la suma anterior (antes usabamos la sigmoide para el ejemplo). Debe ser derivable.
- $y_n$ es la salida de la neurona $n$, calculada a partir de $f(z_n)$.
- $t_n$ es la salida deseada de la neurona $n$. Este valor solo lo sabemos para neuronas de la última capa.
- $\eta$ es el learning rate.
Y lo que queremos calcular es:
$$ \Delta w_{in} = \frac{\partial E}{\partial w_{in}} \qquad \forall i,n$$Donde $\Delta_{in}$ es el cambio que hay que aplicar para entrenar la red en una iteración:
$$ \Delta w_{in} = w_{in}^{(t+1)} - w_{in}^{t} $$¡Vamos allá!
En primer lugar, medimos el error cuadrático de la neurona $k$, que pertenece a la última capa:
$$ E_k = \left( t_k - y_k \right)^2 $$El siguiente paso es obtener su derivada para saber cómo cambiar los parámetros por la regla delta.
$$ \begin{align*} \frac{\partial E_k}{\partial w_{jk}} =& \frac{\partial y_k}{\partial w_{jk}} \frac{\partial E_k}{\partial y_k} \\ =& \frac{\partial y_k}{\partial w_{jk}} \left( -2(t_k - y_k) \right) \\ \end{align*} $$Se calcula la derivada de $y_k$ aparte:
$$ \begin{align*} \frac{\partial y_k}{\partial w_{jk}} =& \frac{\partial f(z_k)}{\partial w_{jk}} \\ =& f'(z_k) \frac{\partial z_k}{\partial w_{jk}} \\ =& f'(z_k) \frac{\partial \left( \sum_j y_j w_{jk} \right) }{\partial w_{jk}} \\ =& f'(z_k) y_j \\ \end{align*} $$Entonces nos queda que:
$$ \frac{\partial E_k}{\partial w_{jk}} = -2(t_k - y_k) f'(z_k) y_j \\[1em] \quad \implies \Delta w_{jk} = \eta (t_k - y_k) f'(z_k) y_j = \eta \Delta_k y_j $$Se ha eliminado el 2 porque ya se considera incluido dentro de la constante $\eta$.
$$ \Delta_k = (t_k - y_k) f'(x_k) $$También se usa la notación $\Delta_k$ dado que es un valor que usaremos más adelante. Se puede interpretar como el error cometido por la neurona $k$ de salida.
Hasta aquí nada nuevo, solo acabamos de rehacer lo de siempre.
Vamos a ver ahora los cambios que hay que hacer en una neurona intermedia. El proceso se complica, ya que $y_j$ contribuye con su valor al error de todas las salidas, no solo la $k$-ésima. Entonces, los cambios en $w_{ij}$ dependen de los errores cometidos en todas las neuronas de la capa de salida:
$$ \Delta w_{ij} = - \eta \sum_k \frac{\partial E_k}{\partial w_{ij}}$$Pues nada, a resolver:
$$ \frac{\partial E_k}{\partial w_{ij}} = \frac{\partial y_k}{\partial w_{ij}} \frac{\partial E_k}{\partial y_k} $$Igual que antes, $\partial E_k / \partial y_k = -2(t_k - y_k)$ y
$$ \begin{align*} \frac{\partial y_k}{\partial w_{ij}} &= \frac{\partial f(z_k)}{\partial w_{ij}} = f'(z_k) \frac{\partial z_k}{\partial w_{ij}} \\[1em] % &= f'(z_k) \frac{\partial \left( \sum_j w_{jk} y_j \right)}{\partial w_{ij}} \\[1em] &= f'(z_k) \frac{\partial \left( w_{jk} y_j \right)}{\partial w_{ij}} \\[2.5em] % Repetir para y_j &= f'(z_k) w_{jk} \frac{\partial y_j}{\partial w_{ij}} \\[1em] &= f'(z_k) w_{jk} \frac{\partial f(z_j)}{\partial w_{ij}} \\[1em] &= f'(z_k) w_{jk} f'(z_j) \frac{\partial z_j}{\partial w_{ij}} \\[1em] &= f'(z_k) w_{jk} f'(z_j) \frac{\partial \left( \sum_i w_{ij} y_i\right)}{\partial w_{ij}} \\[1em] &= f'(z_k) w_{jk} f'(z_j) y_i \\[2.5em] &= x_{ij} f'(z_j) w_{jk} f'(z_k) \\[1em] \end{align*} $$Aquí lo que se ha hecho es ir cambiando por la definición de cada $y$ e ir desenrollando las derivadas hasta llegar al final. Podemos ver que la salida de toda la red ($y_k$) depende de la entrada de la neurona intermedia ($x_{ij}$), la derivada de su cálculo ($f’(z_j)$) y del cálculo de la última capa ($w_{jk} f’(z_k)$). Por eso este método se llama retropropagación del error: el error de las últimas neuronas se envía a las capas anteriores.
Para terminar el cálculo que estábamos haciendo:
$$ \frac{\partial E_k}{\partial w_{ij}} = -2(t_k - y_k) \; f'(z_k) \; w_{jk} \; f'(z_j) \; y_i = -2 \Delta_k w_{jk} f'(z_j) y_i $$Esta es la proyección del error cometido por la neurona $k$-ésima de salida sobre $w_{ij}$. Ahora habría que sumar todas las contribuciones a este peso del error que se produce en el conjunto de neuronas de salida.
Finalmente, generalizando el proceso para todas las capas, desde la salida hasta la de entrada, tendremos las expresiones de ajuste de todos los pesos de la red:
$$ \Delta w_{ij} = - \eta \sum_k \frac{\partial E_k}{\partial w_{ij}} = \eta y_i f'(z_j) \sum_k w_{jk} \Delta_k = \eta y_i \Delta_j $$Donde el $\Delta_i$ de una neurona intermedia $i$ cualquiera se define como:
$$ \Delta_i = f'(z_i) \sum^{i+1}_{j=0} w_{ij} \Delta_{i+1} \qquad $$Siendo $i+1$ la capa siguiente, a la que se le proporcionan los resultados.

Retropropagación del error
El problema principal de este método es la dilución del gradiente: a medida que se van añadiendo más capas ocultas, los cambios en los parámetros afecta más a las últimas capas que a las primeras, lo que no es deseable.
Por ejemplo, en función sigmoidal, cuando toma valores 0 o 1, la derivada es prácticamente 0 y dependemos de ellas para calcular el error.
El pseudocódigo completo es el siguiente:
class RedNeuronal:
f: Function[float] -> float # Función de activación
d: Function[float] -> float # Derivada de f
capas: [[Nodo]] # Nodos de la red ordenados en capas
M: # Número de capas
lr: float # Learning rate
class Nodo:
# NOTA: suponer que cuando se escribe en y, también se escribe en la entrada
# correspondiente del nodo siguiente
y: float # Salida
x: [float] # Entradas
w: [float] # Pesos para cada entrada
class Ejemplo:
X: [float] # Lista de entradas
T: [float] # Lista de salidas deseadas
def retropropagacion(
ejemplos: [Ejemplo],
red: RedNeuronal,
) -> RedNeuronal:
while criterio_fin():
# Inicializar los pesos
for peso in red.w:
peso = small_random()
for X, T in ejemplos:
# La capa 0 contiene las entradas a la red
for i, nodo in red.capa[0]:
# Asignar los valores de entrada a la red
nodo.y = X[i]
# Calcular el resultado de la entrada
z: [[float]]
for m in range(from=1, until=red.M):
for j, nodo in red.capa[m]:
z[m][j] = sum(nodo.w[:] * nodo.x[:]) # multiplicar elemento a elemento
nodo.y = red.f(z[m][j])
delta: [[float]]
# Calcular el error en la última capa
for k, nodo_k in red.capa[red.M]:
delta[red.M][k] = red.d(z[red.M][k]) * (T[k] - nodo.y)
# Calcular el error en el resto de capas
for m in range(from=red.M-1, to=1):
for j, nodo in red.capa[m]:
delta[m][j] = red.d(z[m][j]) * sum(nodo.w[:] * delta[m+1][:])
# Actualizar los pesos de la red
for m in red.capas[1:]:
for j, nodo in red.capa[m]:
for i in range(nodo.w):
nodo.w[i] += red.lr * nodo.x[i] * delta[m][j]
return red
Aprendizaje no supervisado
En la mayoría de casos prácticos que se abordan en el aprendizaje automático pertenecen a la categoría de supervisado, en los que se tienen datos representativos del problema con sus resultados.
Sin embargo, cuando esto no es posible, aparecen los problemas.
En cambio, lo que se hace en el aprendizaje no supervisado es agrupar datos no etiquetados a partir de regularidades, patrones, etc. Al final, son los propios datos del problema los que dictan cómo resolverlo.
- Se aprender sobre datos no etiquetados
- El diseñador le asigna el significado (pertenencia) y su valor (utilidad)
- Se aprender identificando determinadas estructuras en los datos
- Es el tipo de aprendizaje automático después del supervisado más usado
$K$-medias
Es el método de aprendizaje no supervisado más intuitivo y simple. Tiene multitud de variantes, pero vamos a ver lo más elemental.
Suponer un conjunto de datos de 2 variables y los representamos sobre un gráfico. Imaginemos que queremos agruparlos en 3 grupos en función de esas 2 características.
A continuación, seleccionamos 3 elementos de forma aleatoria que serán de centroides de las agrupaciones. A partir de esas referencias, se itera por todos los datos para encontrar el centroide más cercano a cada uno.
Para ello, se pueden usar diferentes criterios, como por ejemplo la distancia euclídea, pero eso depende en alta medida del problema a resolver. Este será el criterio que defina la formación de los grupos o clusters.
A continuación, ya teniendo los grupos formados, se recalcula la posición del centroide tomando la media de las distancias a todos los elementos de su agrupación.
Este proceso se repite continuamente hasta que hay pocos cambios en las posiciones de los centroides.

Proceso iterativo del algoritmo de $K$-medias
Veamos ahora el algoritmo más formalmente:
Entradas:
- $K$ es el número de clusters
- $x = \set{x^{(1)}, \ldots, x^{(m)}}$ es el conjunto de entrenamiento, con $x^{(i)} \in \R^n$ ($n$ es el número de variables de entrada).
Sean:
- $c^{(i)} \in {1, \cdots, K}$ el índice de cluster al que se le ha asignado el valor de entrada $x^{(i)}$ temporalmente.
- $\mu_k \in \R^{n}$ es el centroide del agrupamiento $k$
- $\mu_{c^{(i)}}$ es el centroide del agrupamiento al que se le asignó el elemento $x^{(i)}$
Objetivo a optimizar o medida de rendimiento:
$$ J(c^{(1)}, \ldots, c^{(m)}, \mu_1, \ldots, \mu_K) = \frac{1}{m} \sum^m_{i=1} || x^{(i)} - \mu_{c^{(i)}} || ^2 $$ $$ \min_{\substack{c^{(1)}, \ldots, c^{(m)}, \\ \mu_1, \ldots, \mu_K}} J(c^{(1)}, \ldots, c^{(m)}, \mu_1, \ldots, \mu_K) $$Tenemos un proceso de agrupamiento cuyo objetivo es minimizar la distancia entre los puntos asociados a un agrupamiento.
centroides = {random() repeat K times}
num_iter = 0
while num_iter >= NUM_ITER:
num_iter = num_iter + 1
# Recalcular los clusters para cada dato
for i=1 to m:
c[i] = indice_centroide_mas_cercano_a(x[i], centroides)
# Recalcular la posición de los centroides
for k=1 to K:
elementos_cluster = x[filtrar(c, lambda e: e == k)]
centroide[k] = posicion_media(elementos_cluster)
Otro criterio para detener el algoritmo es calcular la distancia que se han movido los centroides, y cuando sea un valor pequeño, terminar.
El principal problema de este método es que el resultado depende enormemente de la posición inicial de los centroides. Algunas posibilidades:
- Distinguir a ojo los agrupamientos y seleccionarlos a mano (no sirve cuando hay muchas variables: no se pueden visualizar tantas dimensiones).
- Si tenemos suerte de inicializar bien los centroides, el proceso será óptimo y rápido.
- Si partimos de una mala distribución inicial, el algoritmo se quedará estancado y no realizará la correcta agrupación.

Lo que se suele hacer el ejecutar el problema muchas veces y seleccionar el mejor de los resultados, dependiendo del coste computaciones y la cantidad de datos disponibles.
Otro problema es la sección del número de clusters óptimo. La solución trivial (según la medida de rendimiento propuesta antes) es tener un cluster por cada dato individual, $K = m$, donde el error será nulo. Sin embargo, no se trata de una solución muy útil, evidentemente no diseñamos un sistema para que al final nos diga que tenemos tantos conjuntos como datos.
Si no tenemos un número específico, deberemos buscar el mínimo número que represente bien todos los datos. Para ello, habitualmente se usa el método del codo.
En una gráfica mostramos el coste calculado por la función $J$ respecto al número de $K$ de clusters, para ver qué número es el que más nos beneficia.

Ejemplo de una gráfica Coste-Clusters
Para unos pocos clusters el coste será alto, pero a medida que se van añadiendo, coste disminuye rápidamente hasta llegar a un punto de inflexión. A partir de ahí, seguir añadiendo agrupaciones no nos beneficia tanto como antes.
Este punto de inflexión o «codo» se utiliza muchas veces como criterio práctico para encontrar una solución de compromiso. Sin embargo, puede haber casos donde dicho punto no esté claro o haya varios de ellos.
Nótese que aquí también es necesario realizar un preprocesado de los datos, como normalizarlos para tenerlos en el mismo rango (se están tomando distancias sobre ellos).
Es bastante fácil que entre los datos de entrenamiento existan outliers, que son puntos atípicos en el conjunto de datos debidos a errores de medida o otros motivos. Estos puntos distorsionarán la solución, y lo mejor es descartarlos del conjunto de entrenamiento.