Modelo Cliente-Servidor
En el modelo Cliente-Servidor, el servidor es una fuente fiable y bien conocida de datos, que espera de forma pasiva mensajes y conexiones de clientes. Los clientes inician el intercambio de mensajes y simplemente se limitan a pedir datos.
Se trata del modelo más popular usado en la actualidad, sobre todo para servicios web, HTTP y otros (FTP, DHCP, …).
Limitaciones del modelo Cliente-Servidor:
- Escalabilidad: el servidor es un cuello de botella. A medida que el número de clientes crece, nos vemos obligados a incrementar la potencia del servidor para atender a todos los clientes.
- Único punto de fallo: si el servidor no funciona, no se puede ofrecer el servicio.
- Requiere administración: se necesita a alguien responsable de que el servidor funcione en todo momento y realizar tareas de mantenimiento de forma periódica.
- Recursos sin usar: normalmente los clientes pueden colaborar en parte de los cálculos necesarios, es decir, hay potencia de cálculo disponible que no se está utilizando.

Una posible estrategia para distribuir el tráfico son los DNS
Introducción a las Redes P2P
Las redes Peer-to-Peer intentan resolver las limitaciones del paradigma del Cliente-Servidor. Consiste en la compartición de recursos y servicios (información, procesamiento, almacenamiento de disco) mediante el intercambio directo entre sistemas que tradicionalmente eran los clientes.
Una red P2P está compuesta de máquinas (llamadas nodos o pares) conectadas mediante una red.
Todos los nodos son idénticos a nivel lógico
Cada nodo aporta (con distintas capacidades):
- Potencia de cómputo
- Capacidad de almacenamiento
- Contenido
Todo nodo puede actuar como:
- Servidor: Proveen de recursos.
- Cliente: Consumen recursos.
- Router: Reenvían datos a otro nodo. Punto intermedio con un tercero.
Por tanto, cualquiera puede iniciar la conexión.
Cada nodo es autónomo: no necesitan administración por parte de un tercero y tiene sus propios intereses: compiten y colaboran.
La red es dinámica: se añaden o quitan nodos frecuentemente.
Características principales:
- Utiliza los recursos ya existentes en la red: los clientes
- No hay una fuente centralizada de datos: los recursos están distribuidos
entre varios clientes.
- “La forma definitiva de democracia en Internet”
- “La amenaza definitiva a los derechos de autor en Internet”
==> Estas redes suelen tener problemas por el incumplimiento del copyright.
Ventajas frente al modelo Cliente-Servidor:
- Uso eficiente de los recursos
- Escalable
- Los consumidores también donan recursos
- Los recursos crecen naturalmente con el uso
- Más fiable
- Existen réplicas de información
- Distribución geográfica
- No hay un único punto de fallo
- Fácil administración: no hay administración
- Los nodos son autónomos y auto-organizados
- Diseñado para ser a prueba de fallos: réplicas, distribución de la carga…
Ejemplos notables
- Compartición de archivos a gran escala: cada nodo puede ofrecer sus
archivos y descargar de otros nodos. Esto puede conllevar a problemas de
copyright.
Ejemplos: Napster, Gnutella, Freenet, Kazaa - Algunos videojuegos multijugador.
- Apps colaborativas , aunque depende de la arquitectura que usen.
Napster
Creada inicialmente para compartir música con otros usuarios.
Tenía un servidor central para realizar búsquedas:
- Cuando un cliente se conecta, indica su IP y los archivos que tiene disponibles.
- El servidor verificará que el archivo es correcto mediante un resumen digital. Es decir, que si el usuario asegura tener el archivo A, pero el resumen digital no coincide con de otros usuarios, se deniega.
- Otros clientes pueden realizar consultas con el servidor y buscar quienes tienen una copia del archivo.
La descarga se realiza por bloques (cuando el archivo es grande), con el propósito de agilizar la descarga:
- B1 de la máquina A
- B2 de la máquina B
- …
- La máquina receptora compone los bloques
Sin embargo, cuando los usuarios de la red empezaron a infringir el copyright, cerraron el servidor, el principal punto de fallo. Por tanto, se cayó toda la red dado que no se podían hacer consultas. El servidor también era el cuello de botella del sistema, y era susceptible a ataques DDoS (denegación de servicios).

Ejemplo de una red de Napster
En la red P2P de compartición de música Napster, se usan dos modelos distintos:
- Cliente-Servidor para las consultas de archivos.
- P2P para la descarga. Para acelerar el proceso se descargan por bloques.
El problema es que el servidor era el cuello de botella y el principal punto de fallo.
Lo que es un claro ejemplo de una aplicación que se rige por varios modelos de la computación distribuida.
Gnutella
Se trata de una mejora de Napster muy utilizada tras su caída en 2001; y pensada para compartir todo tipo de archivos, no solo música.
Se trata de un sistema completamente P2P, ya que utiliza un método de búsqueda descentralizada, para no depender de un servidor. Por tanto, en principio no es susceptible a ataques [DDoS] y es muy difícil tumbar toda la red: si se apaga uno de los nodos, sea cual sea, la red sigue funcionando.
Aún así, este sistema tiene sus propios problemas: conocimiento de otros nodos, flooding queries, verificación de los resultados…
El funcionamiento es el siguiente:
- El cliente pregunta a sus vecinos más cercanos por archivos de su interés.
- Estos hacen lo mismo y reenvían la petición a otros (función de router), esencialmente distribuyendo el mensaje por toda la red.
- Aquel usuario que tenga el archivo correcto, responderá directamente con la máquina que lo buscaba.
Esto puede ser un problema por generar tanto tráfico, por lo que estos mensajes llevan un TTL (Time To Live) que se decrementa con cada salto y al llegar a 0 no se reenvía. Con esto se limita un máximo de x saltos, lo que permite localizar la búsqueda a un área geográfica en concreto.

Ejemplo de búsqueda en una red Gnutella
Principales problemas:
- El principal problema es tener conocimiento a priori de otras máquinas de la red: ¿cómo conozco a mis vecinos a quienes consultar?
- No se pueden verificar resultados correctos: un nodo malicioso puede suplantar archivos por otros.
- El sistema de búsqueda genera bastante tráfico de mensajes, por lo que
sigue sin ser super-escalable.
Si un usuario malicioso comienza a lanzar peticiones de búsqueda todo el rato con TTLs grandes, puede afectar al rendimiento de un número ilimitado de máquinas (flooding queries).
Existen dos tipos de free-riding:
- Descargando contenido pero sin aportar nada propio
- No aportan nada interesante para el resto
La compartición de archivos depende de que sean los usuarios los que compartan sus datos. Sin embargo, según estadísticas realizadas, el 15% de los usuarios distribuyen el 94% del contenido. El 63% nunca respondieron a una consulta, dado que no tenían nada interesante.
Kazaa
Se trata de un híbrido entre Napster y Gnutella, que intenta buscar lo «mejor de los dos mundos». Utiliza un protocolo llamado Fasttrack.
Se añade el concepto de super-peer:
- Centro de búsqueda local, responsables de una zona geográfica. Funcionan como el servidor de Napster a una escala más pequeña, solo para nodos cercanos.
- Son dinámicos y se seleccionan automáticamente en función de sus capacidades: conectividad, CPU, memoria y disponibilidad (tiempo conectado).
- Contienen una lista de archivos disponibles y los usuarios que los tienen.
- Existe comunicación entre varios super-peers para mantener la BD actualizada, sobre todo cuando se cambia de super-peer.
El funcionamiento para los clientes en idéntica que en Napster.
- Para que un cliente se pueda conectar, necesita conocer alguno de estos servidores.
- El cliente dialogará con el servidor para conectarse: compartiendo la lista de sus archivos.
- Luego, se le realizan peticiones para realizar búsquedas

Comparativa entre las topologías de Napster, Gnutella y Kazaa
Freenet
Estar conectado a una red P2P no necesariamente implica que sus usuarios son anónimos.
- Un cliente tiene una copia.
- Informa al super-peer o servidor central, lo que deja registro en un log.
- Otros clientes consultan el super-peer o servidor central para encontrar archivos, lo que también puede dejar logs. En el caso de Gnutella, el emisor de la petición es conocido por todos.
- Durante la descarga, el cliente puede ver quién se lo está enviando.
Una posible estrategia por las autoridades es publicar «contenido interesante», y establecerse como super-peer para recibir consultas de los usuarios junto con su dirección IP, desde la que se puede obtener la dirección física a partir del suministrador de acceso a internet.
A diferencia de las anteriores, Freenet es una red P2P cuyo objetivo principal es la compartición de archivos manteniendo a sus usuarios anónimos.
Las consultas se enrutan a través de distintos nodos (forwarding), es decir, será el nodo siguiente quien repita la consulta. Así, cuando recibo una consulta, no sé si el nodo es intermediario o si es el emisor original.
Se utiliza un algoritmo de búsqueda incremental (discovery) para encaminar las consultas hacia el nodo correcto. En cada nodo se comprueba los caminos por los que puede reenviar la consulta y descartar callejones sin salida y bucles.

Ejemplo de consulta inteligente
Suponemos que el nodo A quiere pedir determinada información que tiene el nodo D.
- Primero, el nodo A hace una consulta al nodo B.
- El nodo B tiene tres conexiones: C, E y F.
- Primero, B repite la consulta a C. Como este no tiene más conexiones, y no tiene la información, le indica que no.
- Después, B repite la consulta a E, que está conectado a F y D.
- E repite la consulta con F. Como F está conectado con B, también se la reenvía a él.
- Como B está en medio de esta consulta, detecta un ciclo y la cancela, lo que se propaga también hasta E.
- E envía ahora la consulta a D, que responde con los datos deseados.
- Cuando E recibe los datos, los envía de vuelta a quien le hizo la consulta, B en este caso.
- B recibe los datos y los envía de vuelta al nodo inicial A.
- A recibe los datos que pidió desde B, pero no sabe que fue D realmente quien los tenía.
Para realizar la descarga, los flujos de datos circulan en la ruta inversa a la consulta: se devuelven al intermediario.
Lógicamente, esta estrategia genera más tráfico, pero:
- Es imposible saber si un usuario está iniciando o reenviando una consulta.
- Es imposible saber si un usuario está consumiendo o reenviando información.
- Entonces, para que las autoridades puedan rastrear el original, se debe tener acceso a todos los registros de los nodos y contrastarlos.
Redes P2P estructuradas
En las redes P2P no estructuradas, los enlaces son arbitrarios. Si un usuario desea encontrar información específica, la petición debe recorrer toda la red.
Por otro lado, las redes P2P estructuradas son la nueva generación de este paradigma. Se utilizan mayoritariamente en entornos empresariales, donde están obligados a distribuir la información de forma equitativa. Esta clase de sistemas son los que generan el mayor tráfico de todo internet.
Características:
- Auto-organizativas al añadir y quitar nodos.
- Balance de carga: todos los nodos tienen la misma carga. En las redes anteriores esto no se garantiza.
- Tolerantes a fallos.
- Escalables: garantizan un máximo número de saltos para obtener una respuesta. Tampoco se garantiza en las redes anteriores.
- Basados en una tabla hash distribuida.
Por tanto, el sistema P2P es un conjunto de nodos con una API para poder acceder a esa tabla hash distribuida.
Distributed Hash Table (DHT)
Se trata de la versión distribuida de una estructura de datos tabla hash.
- Tendremos pares de elementos tipo
(clave, valor), donde normalmente la clave será el nombre del archivo, y el valor su contenido. - El objetivo es realizar inserciones, búsquedas y borrados de la forma más eficiente posible.
Cada nodo de la red será responsable de un subconjunto de pares clave-valor, y el tamaño será aproximadamente el mismo para cada todos, consiguiendo así distribuir la carga.
Las búsquedas consistirán en encontrar el nodo responsable a partir de la clave.
Interfaz genérica de DHT
id: secuencia de m-bits para identificar del nodo, equivalente a una dirección IP. En función de cuantos nodos tenga, usaré más o menos bits.key: secuencia de bytes que representa el nombre de un archivo.value: secuencia de bytes que representa el contenido del archivo.
Las operaciones son las siguientes:
- Inserción:
put(key, value). Almacena dicha pareja en el nodo correspondiente según el algoritmo utilizado. - Obtención del valor:
value = get(key). Se accede al nodo responsable para obtener la información deseada.
Se pueden construir muchos servicios sobre una interfaz DHT:
- Compartición de archivos
- Almacenamiento de archivos
- Bases de datos
- Nombramiento, descubrimiento de recursos
- Servicio de chat
- Comunicación basada en rendezvous (reunión)
- Publica-Suscribe
Características deseables:
- Claves distribuidas equitativamente por todos los nodos, para balancear la carga.
- Cada nodo solo mantiene información sobre otros pocos nodos, ninguno almacena la red completa.
- Los mensajes se pueden enrutar de forma eficiente a un nodo concreto.
- La inserción/eliminación de nodos debe afectar a muy pocos nodos.
Ejemplos de implementaciones concretas de la interfaz genérica de DHT:
- Chord (MIT)
- Pastry (Microsoft, Rice University)
- Tapestry (UC Berkeley)
- Content Addressable Network, CAN (UC Berkeley)
- SkipNet (Microsoft)
- Kademlia (New York University)
- Viceroy (UC Berkeley)
- P-Grid (EPFL Switzerland)
- Freenet (Ian Clarke)
La mayoría son experimentales y de carácter académico. Se conocen como los sustratos de enrutamiento P2P, soportes para aplicaciones más complejas.
Chord API
Se trata del algoritmo más simple que implementa DHT.
id: hash de n-bits de la IP del nodo y otra información relevante para identificar de forma única el nodo.clave: resumen digital de n-bits del contenido a almacenar.valor: bytes del valor a almacenar.
insert(k, v): inserta un valor en el nodo responsable.update(k, v): igual que insertar, pero para actualizar el dato almacenado.v = get(k): obtiene el valor correspondiente del nodo responsable. Otro posible nombre eslookup(k).join(n): unirse a la red.leave(): salir de la red.

Un sistema con $N$ nodos y $K$ claves:
- Los nodos se organizan consecutivamente en un identifier circle en función
de su
id. - Cada nodo es responsable de como mucho $K/N$ claves.
- Cada nodo tiene una tabla (a veces llamada finger table) que almacena los $O(\log_2 N)$ nodos siguientes.
Funcionamiento:
Asignación de claves a nodos: la clave $k$ se asignará al nodo número $k$ si está disponible, o a aquel nodo inmediatamente superior a $k$. Por tanto, la clave $k$ estará en un nodo $n$ de forma que $k \le n$.
Completar la tabla: el nodo $n$ almacena la dirección del nodo que almacena la clave $n + 1, n + 2, n + 4, \ldots, n + 2^i$. Se detiene cuando se supera el número de nodos totales $N$.
Por ejemplo, a partir del nodo 8:
Clave Nodo $N8 + 1$ $N14$ $N8 + 2$ $N14$ $N8 + 4$ $N14$ $N8 + 8$ $N21$ $N8 + 16$ $N32$ $N8 + 32$ $N42$ 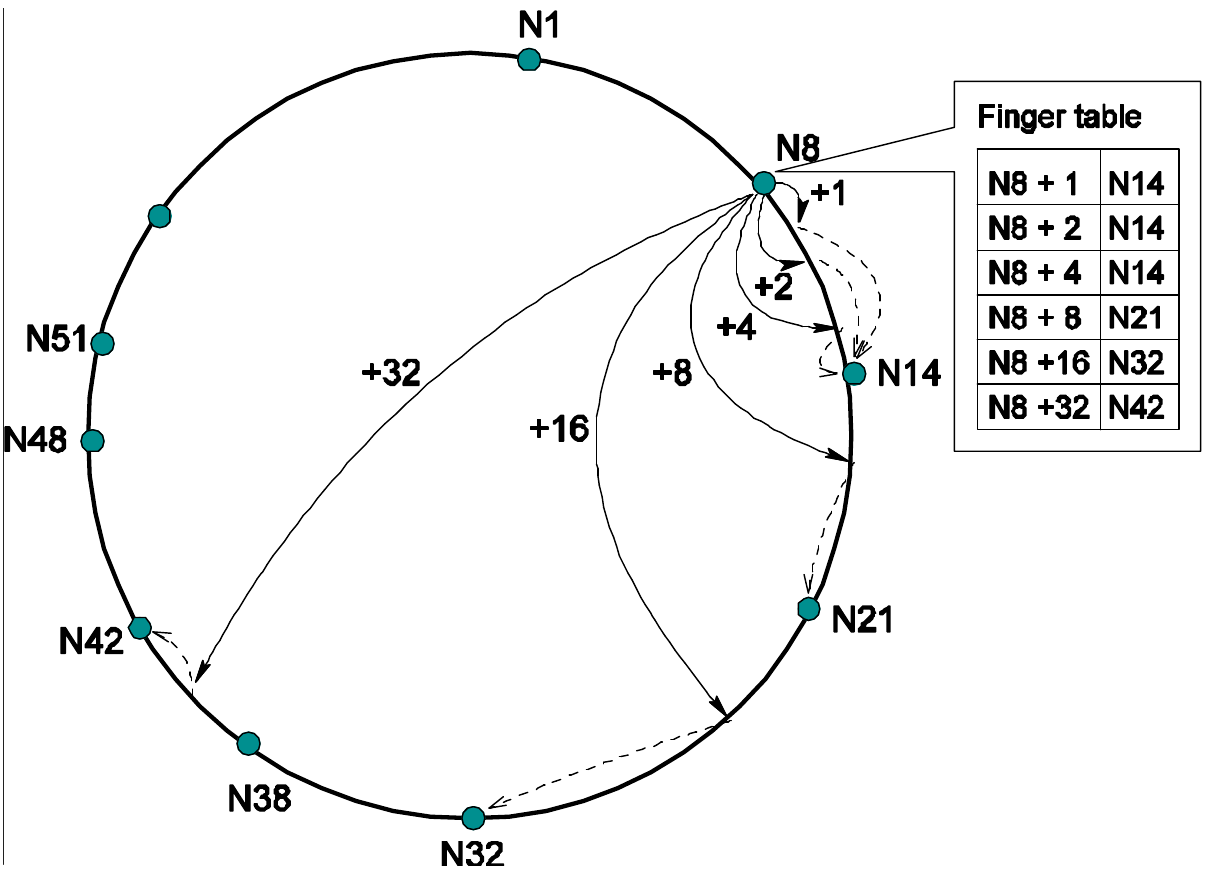
Nótese que la tabla almacena con mayor precisión los nodos siguientes próximos, pero los más alejados no (función exponencial).
Búsqueda de $k$: el nodo mira en su tabla y si no hay nodo $k$, pregunta al nodo con el
idmenor más cercano. Este realizará el mismo proceso hasta dar con el nodo que tenga el valor correcto.Este mecanismo es esencialmente una búsqueda binaria, por lo que se completa en $O(\log_2 N)$

Problemas y desventajas:
- No se garantiza encontrar el dato.
- No garantiza la consistencia entre réplicas.
- Localidad espacial muy pobre. Los nodos próximos en el círculo pueden estar físicamente lejos, lo que supone un retardo elevado.
Otras implementaciones
| Otras implementaciones | |
|---|---|
| Pastry |
|
| CAN |
|