Necesidad de un sistema de archivos
Nótese que, una vez que un proceso termina, toda la memoria relacionada con él (su espacio de direcciones o segmentos) se borran, lo que es inaceptable para algunas aplicaciones (p.e.: Bases de Datos).
En general, tenemos 3 requisitos esenciales para el almacenamiento de información a largo plazo:
- Debe ser posible almacenar una gran cantidad de información.
- La información debe persistir tras la terminación del proceso que la utilice.
- Múltiples procesos deben poder acceder a la información de forma concurrente.
Los discos son los dispositivos que se utilizan para este almacenamiento a largo plazo, lo que permiten (entre otras) dos operaciones básicas:
- Leer un bloque
- Escribir un bloque
Lo que no es muy satisfactorio:
- ¿Cómo sabemos qué bloques están libres?
- ¿Cómo se gestionan los sistemas con muchas aplicaciones y usuarios?
- ¿Cómo evitamos que un usuario lea datos de otro?
- ¿Cómo se encuentra la información?
- …
Además, ya se ha visto en la introducción que los dispositivos de E/S, en especial los discos, son bastante complejos de gestionar.
Abstracción del sistema de archivos
Archivo
Al igual que con los procesos y el espacio de direcciones virtuales, el Sistema Operativo soluciona todos estos problemas creando una nueva abstracción: el archivo.
Los archivos son unidades lógicas de información creados por los procesos. Estos pueden leer archivos existentes y crear otros.
La información almacenada en cada uno es persistente: no se ve afectado por la creación o terminación de procesos, solo desaparece cuando su propietario lo elimina.
Cuando un proceso crea un archivo, le da un nombre. La nomenclatura depende un poco de cada sistema:
- Habitualmente se permiten símbolos hasta 255 caracteres.
- Unix diferencia mayúsculas de minúsculas, mientras que para MS-DOS,
ARCHIVO,archivoyarCHiVorepresenta lo mismo.
Muchos sistemas aceptan nombres de archivos en dos partes, separadas por un
punto. La parte que va después del punto se llama la extensión del archivo
y normalmente indica el tipo de archivo: .c indica un archivo de código fuente
C, .zip un archivo comprimido o .pdf un archivo en Formato de Documento
Portable.
- En MS-DOS se permiten de 3 a 8 caracteres para el nombre del archivo y una extensión opcional de 1 a 3 caracteres.
- En Unix, la extensión también es opcional y puede ser de longitud variable.
Estas extensiones son solo convenciones, el Sistema Operativo no las impone. Son más bien un recordatorio para el usuario o impuestas por algún programa en concreto. Aun así, Windows es consciente de las extensiones: los usuarios o procesos pueden registrar extensiones y especificar a qué programa corresponden.
- FAT-16 MS-DOS: Win95 Win98
- FAT-32: evolución de FAT-16
- NTFS MS-DOS: WinNT, Win2000, WinXP
Los primeros sistemas solo proporcionaban acceso secuencial, sin posibilidad de saltar datos; aunque sí que podían rebobinarse para leerlo las veces necesarias. Esto se debe al uso de cintas magnéticas en el pasado.
Hoy en día, en cambio, prácticamente todos los sistemas proporcionan acceso
aleatorio a los datos de un archivo (seek).
El Sistema Operativo lleva registro de información sobre el archivo:
- Protección
- Contraseña
- Creador
- Propietario
- Hora de creación
- Hora del último acceso
- Tamaño actual
- Tamaño máximo
- Banderas (flags): oculto, sistema, solo lectura, binario, temporal, etc
- …
| Llamadas al sistema para el manejo de archivos | |
|---|---|
create | Creación de un archivo vacío dados algunos atributos. |
delete | Borra el archivo dado. |
open | Antes de usar un archivo se debe abrir, para que el SO haga las preparaciones necesarias; como llevar los atributos a memoria para su rápido acceso y actualizar la tabla de procesos. |
close | Una vez terminado el trabajo con el archivo, se debe cerrar para que el SO libere recursos. |
read | Leer un determinado número de bytes del archivo desde la posición actual en el archivo y la dirección de memoria de dónde colocarlos. |
write | Escribir datos en la posición actual del archivo.
|
append | Agrega datos al final del archivo. Es un tipo de write. |
seek | Reposiciona el apuntador dentro del archivo, para hacer lecturas o escrituras en otro lugar. |
get attributes y set attributes | Proporciona un forma a los procesos para obtener y modificar los metadatos de
un archivo. Un ejemplo, es el programa make, que comprueba los tiempos de
modificación; o el programa chmod, que modifica los permisos de un archivo. |
rename | Permite dar un nuevo nombre. No es completamente necesaria: se puede copiar el archivo, darle el nombre nuevo y borrar el anterior. |
Ejemplo de uso de estas llamadas:
// Programa Linux para copiar archivos: copyfile input output
// NOTA: la verificación y reporte de errores es mínimo
#include <sys/types.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#define TAM_BUF 4096
#define MODO_SALIDA 0700 // rwx --- ---
int main(int argc, char** argv) {
if (argc != 3) exit(1); // Error de sintaxis
char buffer[TAM_BUFF];
// Abrir los archivos
int fd_input = open(arg[1], O_RDONLY); // Abrir input solo lectura
if (fd_input < 0) exit(2); // Error al abrir input
int fd_output = creat(arg[1], MODO_SALIDA); // Crear output
if (fd_output < 0) exit(3); // Error al abrir output
// Bucle de copia
while (1) {
// Lee un bloque de datos al buffer
int bytes_leidos = read(fd_input, buffer, TAM_BUF);
if (bytes_leidos == 0) break; // Fin de archivo
if (bytes_leidos < 0) exit(4); // Error
// Escribe en el archivo de salida
int bytes_escritos = write(fd_output, buffer, bytes_leidos);
if (bytes_escritos <= 0) exit(5);
}
// Cierra los archivos
close(fd_input);
close(fd_output);
exit(0);
}
Los enteros fd_input y fd_output son dos descriptores de archivos (File
Descriptors) que se usan para hacer referencia a cada archivo.
Tipos de archivos
- Archivos regulares: contienen información del usuario
- Texto: se usan distintos caracteres para marcar el final de la línea y diferentes formatos para codificar el texto. El más común es UTF8.
- Binarios: tienen una estructura interna que los programas utilizan. Un campo muy común es el número mágico, que indica el tipo de archivo que es.
- Directorios: sistemas de archivos para dar una estructura a los archivos
- Archivos especiales de caracteres: se relacionan con dispositivos E/S en serie
- Archivos especiales de bloque: se usan para modelar discos
Permisos
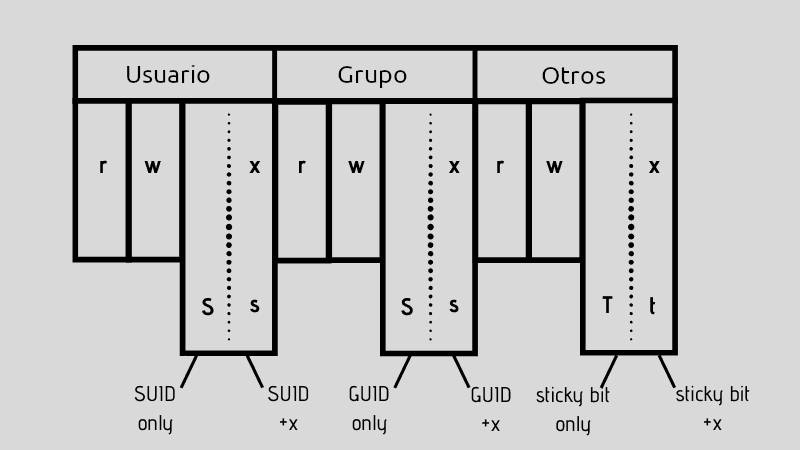
Modos de un archivo
Cada archivo tiene asociada una máscara de 16 bits, llamada la máscara de
modo. La llamada al sistema chmod permite cambiarla.
- Los 3 bits
rwxde menos peso de permisos que aplican a otros usuarios. - Los 3 bits
rwxsiguientes al grupo propietario. - Los 3 bits
rwxsiguientes al usuario propietario. - Los 3 bits siguientes indican permisos especiales.
- Los 4 bits de más peso indican el tipo de archivo (regular, plano, bloque, carácter o link)
Los tres octales (otros, grupo y propietario) aplican todo tipo de archivos, pero tener un efecto diferente dependiendo si es un archivo normal o un directorio. Puede consultar la tabla completa en la ArchWiki.
- Lectura en directorios (
l): permite listar su contenido. - Escritura en directorios (
w): permite crear, renombrar o borrar elementos. Require el bitx. - Ejecución en directorios (
x): permite acceder usandocd.
Los permisos especiales solo son aplicables a determinados tipos de archivos:
- Sticky bit (
S_ISVTX): indica la compartición del segmento de código, por lo que debe mantenerse en memoria. Sin embargo, hoy en día no se usa para eso, sino para directorios. Significa que los elementos de ese directorio solo pueden ser renombrados o borrados por su propietario. Se muestra unaten el comandols. - SGID (
S_ISGID): cambiar el EGID al ejecutar. Se muestra unasen el comandols. - SUID (
S_ISUID): cambiar el EUID al ejecutar. Se muestra unasen el comandols.
Si al usar ls aparece una S mayúscula, quiere decir que hay un error:
probablemente el archivo no es ejecutable. No tiene sentido activar el bit
SUID en un archivo no ejecutable. Lo mismo sucede con el sticky bit, T
cuando el directorio no es ejecutable.
El funcionamiento del usuario real y efectivo se explica en más detalle en el siguiente apartado.
En resumen:
| Permiso | Octal | Archivo | Directorio |
|---|---|---|---|
Ejecución (x) | 1 | Ejecutar | Entrar |
Escritura (r) | 2 | Modificar | Crear/Borrar archivos |
Lectura (r) | 4 | Modificar | Crear/Borrar archivos |
Sticky bit (T, x+T=t) | 1 | - | Solo los dueños pueden borrar sus archivos |
setuid (S, x+S=s) | 2 | Establece el EUID al del dueño | Establece el EUID al del dueño |
setgid (S, x+S=s) | 4 | Establece el EGID al del dueño | Establece el EGID al del dueño |
Identificadores de Usuario y Grupo
Ya sabemos que un fichero ejecutable contiene todas las instrucciones y datos necesarios para el programa. Este tiene también una máscara de modo. Cuando se ejecuta, aparte del PID, tiene asociados dos identificadores de usuario y dos de grupo. Son dos enteros positivos.
UIDyEUID: identificador de usuario real y efectivo respectivamenteGIDyEGID: identificador de grupo real y efectivo respectivamente
Vamos a centrarnos en el identificador de usuario, ya que para el identificador de grupo es análogo.
UID: es el usuario responsable de la ejecución del proceso (quien ejecuta)EUID: es el usuario que se usa para determinar el propietario de los ficheros creados, comprobar si tiene los permisos para acceder a determinados ficheros, permisos para enviar señales, etc.
Es decir: el usuario real es quien ejecuta el programa y un proceso solo puede trabajar con los archivos que pueda acceder el usuario efectivo.
Vale, pero… ¿quién es el usuario efectivo? Esto lo determina por el bit
SUID. Si un ejecutable tiene el bit SUID=1, el EUID pasa a ser el
propietario del programa.
Además, mediante las llamadas al sistema setuid y setgid se puede cambiar el
EUID, pero su funcionamiento es algo particular. Para consultar los valores se
usan getuid, geteuid, getgid, getegid.
Tenga en cuenta que en la mayoría de los casos, UID = EUID.
#include <fcntl.h>
salida = setuid(par);
El EUID del proceso que efectúa la llamada es el superusuario. Entonces,
UID = paryEUID = par. El superusuario tiene permisos para acceder a cualquier cosa, incluso sinSUID. Nótese que también se cambia el usuario real.Si EUID no es el superusuario. Se establece
EUID = parsi:pares el UID del proceso (yo,getuid) ==> Yo voy acceder a mis archivosSUID = 1ypares el UID del propietario del archivo ==> Me hago pasar por el propietario del programa (EUID por defecto cuandoSUID=1).
Se devuelve 0 si se ha cambiado el EUID de forma exitosa o -1 si ha ocurrido
algún error. Puede consultarlo con perror.
Considere el siguiente directorio:
-rwxrwxr-x 1 user1 ... exe
-rw-rw---- 1 user1 ... mi_archivo.txt
-rw-rw---- 1 user2 ... otro_archivo.txt
Puede ver que el usuario 1 es propietario de un archivo ejecutable y un archivo de texto, mientras que el usuario 2 solo es propietario de otro archivo de texto.
Suponiendo que ambos usuarios están en grupos distintos, user1 no puede
acceder a otro_archivo.txt, ni user2 puede acceder a mi_archivo.txt. Por
otro lado, ambos pueden ejecutar exe.
Suponga que exe recibe un archivo por parámetro y lo imprime por pantalla.
Si user1 ejecuta exe mi_archivo.txt, por tanto, el usuario real y efectivo
del proceso es user1. Cuando solicita abrir el archivo para leerlo, se le
concede el acceso dado que el EUID tiene permisos. Sin embargo, si user1
ejecuta exe otro_archivo.txt, el Sistema Operativo devuelve un error, porque
el EUID no tiene suficientes permisos.
Hasta aquí, no debería haber problema: esto es igual que antes, pero usando un proceso.
Suponga ahora que se ha añadido el bit de SUID al ejecutable:
-rwsrwxr-x 1 user1 ... exe
-rw-rw---- 1 user1 ... mi_archivo.txt
-rw-rw---- 1 user2 ... otro_archivo.txt
Si ahora user2 ejecuta exe mi_archivo.txt, el EUID pasa a ser el
propietario del archivo ejecutable: user1. Como consecuencia, el usuario
2 puede leer el archivo mi_archivo.txt.
Además, tenga en cuenta que si user2 ejecuta ahora exe otro_archivo.txt, se
le denegará el acceso, porque el EUID (user1) no tiene acceso
a otro_archivo.txt.
-rwsrwxrwx user1 ... exe
-rw------- user1 ... fichero1.txt
-rw------- user2 ... fichero2.txt
Suponga que el UID de user1 y user2 son 501 y 502 respectivamente.
// Código del programa EXE
#include <fcntl.h>
int main() {
int x, y, fd1,fd2;
x = getuid(); y = geteuid();
printf("\nUID=%d, EUID=%d\n", x, y);
fd1 = open("fichero1.txt", O_RDONLY);
fd2 = open("fichero2.txt", O_RDONLY);
printf("fd1=%d, fd2=%d\n", fd1, fd2);
setuid(x);
printf("UID=%d, EUID=%d\n",getuid(),geteuid());
fd1 = open("fichero1.txt", O_RDONLY);
fd2 = open("fichero2.txt", O_RDONLY);
printf("fd1=%d, fd2=%d\n", fd1, fd2);
setuid(y);
printf("UID=%d, EUID=%d\n",getuid(),geteuid());
}
Si lo ejecuta user1, naturalmente solo tiene acceso a sus archivos.
UID=501, EUID=501 fd1=3, fd2=-1
UID=501, EUID=501 fd1=4, fd2=-1
UID=501, EUID=501
Si lo ejecuta user2 con SUID=0. Igual que antes, solo tiene acceso a sus
archivos.
UID=502, EUID=502 fd1=-1, fd2=3
UID=502, EUID=502 fd1=-1, fd2=4
UID=502, EUID=502
Pero si user2 vuelve a ejecutar con SUID=1:
UID=502, EUID=501 fd1=3, fd2=-1
UID=502, EUID=502 fd1=-1, fd2=4
UID=502, EUID=501
Directorios
Para llevar registro de los archivos, por lo general se permiten crear directorios o carpetas, que en muchos sistemas también son archivos.
Gracias a la creación de directorios dentro de otros directorios, se crean las jerarquías o árboles de directorios. Estas permiten al usuario organizar sus archivos de una forma bastante natural, mediante agrupaciones. Además, se pueden asignar determinados directorios a cada usuario para establecer permisos y seguridad de los archivos.
| Llamadas al sistema para el manejo de directorios | |
|---|---|
create | Crea un directorio vacío (mkdir) |
delete | Borra un directorio vacío (rmdir) |
opendir | Los directorios se pueden leer, para listar los archivos que contiene. El proceso de abrir un directorio es análogo a abrir un archivo. |
closedir | Análogo a cerrar un archivo. |
readdir | Devuelve la siguiente entrada en un directorio abierto. |
rename | Cambia el nombre al directorio. Análoga a renombrar un archivo. |
link | En algunos sistemas, se permiten crear referencias simbólicas para que un mismo archivo (o directorio) de pueda aparecer en varios directorios a la vez. |
unlink | Elimina una entrada del directorio. Si el archivo solo se encuentra en el directorio actual, se elimina del sistema de archivos. |
Rutas
Cuando los archivos se organizan en una estructura arbórea, ya no se pueden identificar únicamente por su nombre, sino que se utilizan nombres de rutas.
- Ruta absoluta: consiste en el camino de directorios desde el directorio raíz, hasta el archivo deseado.
- Ruta relativa: es el camino de directorios desde el directorio de trabajo actual hasta el archivo deseado.
Cada proceso tiene un directorio de trabajo sobre el que opera y que se usa para las rutas relativas.
Por defecto, se usa el directorio heredado del proceso padre, pero existen llamadas al sistema para cambiar este directorio.
En las rutas relativas, habitualmente se puede hacer referencia al directorio de
trabajo actual con . y directorios superiores con ... Por ejemplo, la ruta
Unix ../../layouts/404.html retrocede dos directorios y obtiene al archivo
HTML dentro del subdirectorio layouts.
La nomenclatura de las rutas también varía de un sistema a otro:
- Windows:
\, p.e.:C:\Programacion\blog\content\so\archivos.md.Ces la unidad (dispositivo) y continuación aparece la ruta. - Unix:
/, p.e.:/home/magno/Programacion/blog/content/so/archivos.md. El directorio raíz se especifica con/.
Implementación
Hasta ahora, se ha visto el funcionamiento de la abstracción creada por el Sistema Operativo. Véase ahora cómo se lleva a cabo.
- ¿Cómo se almacenan los archivos y los directorios?
- ¿Cómo se administra del espacio del disco?
Disco duro
Ya hemos visto en las nociones de hardware de la introducción las diferentes partes de los discos. Vamos a profundizar un poco en su funcionamiento.
- Pueden haber varios discos apilados, e incluso varias unidades a la vez. La controladora debe poder gestionar todas las unidades (búsquedas traslapadas).
- Hay dos cabezas electromagnéticas por cada disco, una por cada superficie.
- Un peine contiene todas las cabezas y se desplaza hacia dentro y afuera de los discos. El disco rota para acceder al resto de datos.
- Cada círculo concéntrico en un disco se llama pista.
- Cada porción de pista se llama sector. Es la unidad mínima de información que permite el hardware.
- Como es un círculo, en las pistas exteriores hay más sectores que en las interiores. Por eso se dividen en cilindros.
El bloque de disco, también llamado cluster, es un grupo de sectores.
Para reducir la sobrecarga de las estructuras de datos en el disco, el sistema de archivos no se asigna sobre los sectores directamente, sino sobre un conjunto de ellos que se considere eficiente. No tienen porqué estar todos seguidos, sino que pueden abarcar más de una pista.
Tamaño del bloque
Debe ser una potencia entera de 2, múltiplo del tamaño del sector. Existen casos donde el bloque el del tamaño del sector. También se debería considerar el tamaño de la página en sistemas paginados.
- Grande: fragmentación interna ==> Se desperdicia espacio (espacio de holgura, slack space). Los archivos usan bloques completos.
- Pequeño: un archivo puede tomar muchos bloques ==> Acceso más lento debido a la búsqueda del sector y las rotaciones mecánicas necesarias.
Benchmarks
Según simulaciones de Tanenbaum, el tamaño promedio de los archivos es 2745 bytes.
- Bloques de 1 KiB: el 30% - 50% de los archivos caben en un bloque.
- Bloques de 4 KiB: el 60% - 70% de los archivos caben en un bloque. El 10% de los archivos más grandes son el 93% los bloques ocupados.
Este último es el recomendado a partir del 2007 por la IDEMA (Asociación Internacional de Unidades, Equipo y Materiales de Disco).
- Latencia $L$: tiempo de colocar el peine electromagnético en la pista adecuada. No es un tiempo constante, depende de la posición actual del peine.
- Retraso de rotación: tiempo que hay que esperar mientras el disco rota para colocar el peine sobre el sector adecuado. Depende de la velocidad de rotación del disco (rpm).
- Tiempo de transferencia de datos $T$.
Por tanto:
$$ L + \frac{t_{\text{rotación}}}{\text{ancho de banda}} + T $$Se intentan meter todos los archivos en la misma pista para reducir la latencia.
Al cambiar de pista, el disco sigue girando. Se tiene en cuenta el tiempo para mover el peine de una pista a otra: donde caiga tras ese tiempo. De esta forma, se pueden seleccionar sectores de forma más eficiente. Esto se llama el desajuste de cilindros.
Por tanto, el sector 0 de cada pista está desfasado de la pista anterior.
Ejemplo de cálculo
Disco de $f = 10\,000$ rpm (frecuencia), $300$ sectores/pista, tiempo de cambio de pista $800 \; \mu s$.
Tiempo de una vuelta (periodo):
$$ \frac{1}{f} = \frac{1}{10\\,000 \text{ rpm}} = \frac{1}{10\\,000 \times \frac{1 \text{ rpm}}{60 \text{ vuelta/segundo}}} = \frac{60}{10\\,000} \text{ segundo/vuelta} = 6 \text{ms/vuelta} $$Tiempo que se tarda en recorrer un sector:
$$ 6 \text{ ms/vuelta} \times \frac{1 \text{ vuelta}}{300 \text{ sectores}} = 20 \\; \mu s \text{/sector} $$Número de sectores que pasan durante el cambio de pista:
$$ 800 \mu s \times \frac{1 \text{ sector}}{20 \mu s} = 40 \text{ sectores} $$Disco físico y lógico
Se diferencian de otros dispositivos como ratones y teclados que transmiten información de carácter a carácter.
Se distinguen varios tipos:
SATA (Serial ATA): Se llaman así porque utilizan el bus SATA. En Linux se identifican como
sd(Sata Disk) y una letra minúscula, en función del orden en el que se descubran (/dev/sdaprimero, luego/dev/sdb).SCSI: Formatos por distintos dispositivos como cintas, CD-ROMS, escáneres, etc, conectados en cadena. Son usados por servidores de altas prestaciones y se identifican de forma similar a los SATA.
IDE o Parallel ATA: Poco usados en la actualidad e identificados como
/dev/hday/dev/hdbpara el controlador primario (esclavo y maestro respectivamente);/dev/hdcy/dev/hddpara el controlador secundario.NVMe (Non Volative Memory express):
- Nuevo protocolo de acceso a unidades no volátiles como SSD basado en el
bus PCI express. Se utiliza para conectar todo tipo de tarjetas y es
mucho más rápido que el bus SATA. NVMe suele usar un conector específico
llamado
M.2. - En Linux se identifican como
/dev/nvmeXnYpZ, dondeXes el controlador,Yes el dispositivo yZes el número de partición.
- Nuevo protocolo de acceso a unidades no volátiles como SSD basado en el
bus PCI express. Se utiliza para conectar todo tipo de tarjetas y es
mucho más rápido que el bus SATA. NVMe suele usar un conector específico
llamado
Un disco lógico es abstracción que el SO ve como una secuencia lineal de bloques accesibles aleatoriamente, cada uno identificado por un número de bloque lógico. El driver traduce los números de bloque lógico a números de bloque físico.
- Un sistema de archivos está contenido por completo en un disco lógico y un disco lógico solo puede contener un solo sistema de archivos.
- En sistemas Unix modernos, un disco lógico puede estar formado por varios discos físicos, lo que da soporte a sistemas de archivos grandes.
- En lugar de contener sistemas de archivos, un disco lógico puede contener un área de intercambio para el almacenamiento temporal de páginas de procesos.
Ejemplos de discos lógicos:
- En un sistema operativo como Windows, una partición funciona como un disco lógico.
- Volumen Lógico en [Logical Volume Management]
- Disco lógico de un sistema operativo virtualizado: los discos que utiliza una máquina virtual y que se almacenan como archivos, también cumplen esta definición.
| Disco físico | Disco lógico |
|---|---|
| Corresponde al hardware real (HDD, SSD). | Es una representación abstracta del almacenamiento. |
| Está limitado por el número de discos instalados. | Puede crearse mediante particiones, LVM, RAID o virtualización. |
Identificado como /dev/sda, /dev/sdb en Linux. | Identificado como /dev/sda1, /dev/mapper/volumen, o letras de unidad (C:). |
| Gestionado por el firmware y el sistema operativo. | Gestionado por software de partición, RAID o LVM. |
Partición
El proceso de particionado consiste en la creación de regiones dentro de un disco. Estas son divisiones independientes del disco, que permite poder manejar las particiones por separado. Es responsabilidad del administrador del sistema decidir qué contiene cada una.
La información sobre las particiones se almacena en la tabla de particiones, que el Sistema Operativo lee antes que cualquier otra parte del disco. Existen varias implementaciones dependiendo del sistema:
Normalmente las particiones se identifican con el pseudo-archivo de su disco
y se le añade un número de partición: /dev/sda4.
Algunos tipos de particiones pueden ser:
Partición de arranque (boot partition): Es una partición primaria que contiene el programa de arranque. Por ejemplo, en Linux, sus archivos (kernel, initrd y GRUB) se montan en
/boot(BIOS Boot Partition o BIOS BP, y EFI System Partition).Partición del sistema: contiene un sistema de archivos con la carpeta del Sistema Operativo (system root). En Linux se monta sobre
/.Partición de intercambio o swap: Sirve de zona de almacenamiento temporal para almacenar páginas de los procesos cuando no quede suficiente RAM. Para más información, ver zona de intercambio.
Como cada partición se comporta como un disco lógico, esto permite la coexistencia varios SO en el mismo ordenador: una partición para cada uno (dual boot).
La herramienta fdisk (entre muchas
otras herramientas)
permite manipular la tabla de particiones para crear, extender y eliminar
particiones.
Más información en la archwiki.
Master Boot Record
En los sistemas BIOS, el primer bloque del disco (512 bytes) se conoce como el Master Boot Record (MBR), fuera de cualquier tipo de partición.
Contiene el código del bootloader del sistema operativo (440 bytes) y la tabla de particiones (al final del bloque). Una de ellas está marcada como activa para arrancar desde ahí.
Debido a esta organización, el MBR limita el tamaño máximo del disco particionado a 2 TiB ($2^{32} \times 512$).
Con el fin de superar esta limitación, se realizó una transición a GUID Partitions Table (GPT).
| Tipos de particiones | |
|---|---|
| Partición primaria | Contiene un sistema de archivos, que se puede identificar por su ID en la tabla
de particiones. Solo se pueden tener hasta 4 de estas particiones, que en Linux
se nombran como /dev/sda1, /dev/sda2, /dev/sda3 y /dev/sda4. |
| Partición extendida Partición secundaria | Se trata de un contenedor de particiones secundarias. Un disco duro solo contener una única partición extendida, en cuyo caso solo puede haber |
| Partición lógica | Solo se pueden situar dentro de una partición extendida, pero puede tener un
número ilimitado de ellas. En Linux se nombran de /dev/sda5 para adelante. |
Puede consultar todos los IDs de las particiones.
Para llevar la cuenta de las particiones lógicas, dado que no están la tabla, cada una lógica tiene un EBR o EPBR (Extended Partition Boot Record) que ocupa su primer sector. Esta describe dos elementos:
- Ubicación y tamaño
- Puntero al siguiente EBR
Este mecanismo tiene las siguientes limitaciones:
- Eficiencia: recorrer una lista enlazada para encontrar una partición determinada.
- Complejidad: más difícil de gestionar que una tabla centralizada.
Windows requiere estar instalado en una partición primaria (no lógica) si intentas hacer dual boot.
GUID Partition Table
El GPT (GUI Partition Table) es el nuevo estándar que sustituye a MBR. Es más fiable y está asociado a sistemas UEFI.
Se almacena en una partición con un tamaño de unos 256-512 MB, pero también crea múltiples copias redundantes a través de todo el disco. También tiene al inicio un Protective Master Boot Record (PMBR) con el propósito de proteger el disco contra sistemas que no soporten GPT y ser retrocompatible.
Es posible utilizarlo en discos mayores de 2 TiB.
Con UEFI se pueden crear hasta 128 particiones primarias (límite impuesto por los sistemas Windows). A cada una de ellas se le asocia un identificador global único (GUID o UUID).
Nótese que las particiones extendidas pueden existir en GTP, pero no se usan porque no tienen mucho sentido.
| Característica | GPT (UEFI) | LVM |
|---|---|---|
| Propósito | Estructura de particiones físicas | Gestión avanzada de almacenamiento lógico |
| Flexibilidad | Estática: no se puede redimensionar sin herramientas adicionales | Dinámica: volúmenes redimensionables fácilmente |
| Compatibilidad | Directamente compatible con el sistema operativo | Necesita soporte en el sistema operativo y configuración manual |
| Redundancia/Integridad | GPT incluye redundancia y CRC para la tabla de particiones | Depende del sistema RAID o la configuración subyacente |
| Número de discos | Diseñado para un solo disco físico | Diseñado para múltiples discos físicos o particiones |
| Escalabilidad | Limitada al número de particiones definidas | Muy escalable; soporta agrupación y redimensionamiento en tiempo real |
Implementación de archivos
Es necesario mantener un registro de la correspondencia de un archivo y de los bloques de disco que contienen su información.
Se mantiene una lista enlazada de bloques de disco, la primera palabra de cada bloque se utiliza como apuntador al siguiente, el último bloque tiene un 0. El resto del bloque es para los datos.
Problemas:
- La lectura secuencial no tiene problemas, pero el acceso aleatorio puede ser muy lento. Para leer el bloque $n$, necesariamente hay que acceder a los $n-1$ bloques anteriores.
- La cantidad de datos almacenados en el bloque ya no es potencia entera de dos. Puede ser problemático, dado que los programas leen/escriben de bloque en bloque.
Se solucionan los problemas de la lista enlazada tomando todos los apuntadores y colocándolos en una tabla, llamada File Allocation Table (FAT).
En la entrada correspondiente al bloque inicial del archivo se almacena la dirección del siguiente bloque. En dicha entrada, se almacena la dirección del bloque siguiente, y así sucesivamente. La cadena termina con un marcador especial, como por ejemplo -1.
- El bloque completo está disponible para los datos.
- La tabla FAT debe estar en memoria principal siempre.
- El acceso aleatorio es más sencillo dado que la tabla está en RAM, aunque aún se tiene que seguir la cadena.
- No escala bien para discos grandes: tablas muy grandes.
Se lleva un registro de qué bloques pertenecen a cuál archivo es asociar cada archivo a una estructura de datos conocida como nodos-índice (inodes).
Esta contiene los atributos del archivo y un array de las direcciones de los bloques. Si hay más bloques de los que se pueden listar en el inodo, hay un puntero a un bloque de apuntadores con el resto de direcciones.
- El inodo de un archivo solo se lleva a memoria cuando se abre.
- El inodo es más pequeño que una tabla FAT: esta se refiere a todos los archivos, mientras que el inodo describe uno.
Esta es la opción utilizada en Unix.
Implementación de directorios
La función principal del sistema de directorios es asociar cada nombre de archivo a la información necesaria para localizar los datos. Muchos sistemas también almacenan en la entrada de directorio de un archivo sus atributos.
Montaje de sistemas de archivos
En Windows, a cada disco lógico se le llama unidad y cada uno puede contener un
sistema de archivos con su propia jerarquía. Se identifican por una letra
mayúscula, donde normalmente C se refiere a donde está Windows instalado.
En Unix es posible tener varios subárboles independientes, cada uno con un
sistema de archivos completo. Sin embargo, uno de ellos se configura para ser
el sistema de archivos raíz y para que su directorio raíz sea el directorio
raíz del sistema. Otros sistemas de ficheros se adjuntan a la estructura
montándolos sobre un directorio ya existente, llamado directorio de
montaje o punto de montaje, gracias a la llamada del sistema mount.
Una vez montado, el directorio raíz de la nueva estructura pasa a ser el
directorio de montaje, y cualquier acceso se traduce al sistema de archivos
montado. Esto permanecerá visible hasta que se desmonte con umount.
// Ver man mount(2)
#include <sys/mount.h>
// Sintaxis en Linux
int mount(const char* device, const char* mountdir,
const char* filesystem_type, // ext4, vfat, proc, tmpfs, ...
unsigned long flags,
const void *_Nullable data);
int umount(const char* device);
// Sintaxis en Unix clásico
mount("/dev/hda2", "/usr", 0);
umount("/dev/hda2");
Alternativamente, desde Bash, se usan los comandos siguientes:
mount /dev/... ruta # Monta la partición en directorio
mount --mkdir /dev/... ruta # Para crear directorio si no existe
mount -a # Monta los fs especificados en /etc/fstab
mount -o ruta opciones # Permite remontar con otras opciones
umount ruta # Desmonta el fs del directorio
Esta noción de montaje, permite ocultar al usuario los detalles de la organización del almacenamiento: las rutas siguen siendo homogéneas y no es necesario especificar ninguna unidad.
El kernel utiliza una tabla de montaje para llevar registro de los sistemas
de archivos montados. Se suele ubicar en /etc/mtab en Linux, mientras que el
archivo /etc/fstab definen las monturas a utilizar en el arranque.
Un ejemplo del /etc/mtab este último es el siguiente (/etc/fstab usa la
misma sintaxis):
# device directory type options dump pass
/dev/hda1 / ext2 defaults 0 0
/dev/hda2 /usr ext2 defaults 0 0
/dev/hda3 none swap sw 0 0 # Zona de swapping
/dev/sda1 /dosc msdos defaults 0 0
/proc /proc proc none 0 0
La primera línea es un comentario:
- La primera columna indica el dispositivo que se monta
- La segunda columna es el directorio de montaje
- La tercera columna es el tipo de sistema de archivos
- Y la última columna contiene diferentes opciones de montaje
Algunas opciones de montaje por defecto son:
rw/ro: se monta con permisos de lectura/escritura (rw)- Se permite la ejecución de archivos ejecutables
- Se interpretan los bits
S_ISUIDyS_ISGID - El sistema de archivos se considera como un dispositivo de bloque
- Todas las operaciones E/S se hacen de forma asíncrona
user/nouser: los usuarios normales no pueden montar el sistema de archivosauto/noauto: se monta automáticamente en el arranque
Nótese que /proc es un sistema de archivos especial. Más información en la
especificación de directorios de linux.
Administración y optimización de Sistemas de Archivos
Hacer que el sistema de archivos es una cosa, que sea eficiente es otra. Véanse ahora algunas ideas para mejorar el rendimiento.
Un parámetro fundamental para ello es el tamaño del bloque, que ya se ha comentado previamente.
Registro de bloques libres
Problema muy similar a la administración de memoria libre, por lo que se utiliza el mismo tipo de estrategias: listas enlazadas y mapas de bits.
Se utiliza una lista enlazada de bloques, donde cada bloque almacena tantos números de bloque libres como pueda. Se mantiene uno de estos bloques en memoria para cuando se necesite escribir algo, y cuando se terminen los bloques libres, se lee el siguiente. Lo mismo cuando se borran archivos: se añaden, y en el momento que se llene, se toma un bloque adicional y el anterior se escribe en el disco.
Si un bloque es de 1 KiB, con 32 bits para poder representar su número; en un bloque pueden caber $2^{10} / 4 - 1 = 2^8 - 1 = 255$ entradas, dado que el último es un puntero al siguiente bloque de la lista.
Generalmente se usan los bloques libres para almacenar esta lista, por lo que el almacenamiento sale gratuito.
Si hay muchos bloques libres contiguos, se puede almacenar la dirección del bloque inicial y cuántos bloques libres hay a continuación, ahorrando aún más en espacio.
Un disco con $n$ bloques requiere un mapa de $n$ bits, donde 1 indica que el bloque está libre y 0 si está ocupado (o viceversa, depende del sistema).
Lógicamente, ocupa mucho menos espacio que la lista enlazada de bloques (si el disco está vacío).
Disco de 500 GB, bloques de 1 KiB $\implies n_b = 500 \times 10^{9} / 2^{10} = 488,281\,250$ bloques.
- Lista enlazada: $2^{10} / 4 - 1 = 255$ entradas $\implies \lceil n_b / 255 \rceil = 1\,914\,829$ bloques, 0.3922% (si el disco está vacío).
- Mapa de bits: $n_b$ bloques $\implies n_b$ bits $\implies \lceil (n_b / 8) / 2^{10} \rceil = 59\,605$ bloques, 0.0122%
[Logical Volume Management]: {{/*< ref “linux/instalacion/#logical-volume-management” */>}}