Comunicación de procesos (IPC)
Con frecuencia, varios procesos deben comunicarse entre sí para pasar datos o coordinarse para hacer una tarea. Por ejemplo, en el Shell, se utilizan pipes para que la salida del primero sea la entrada del segundo.
Hasta el momento, se sabe que los procesos que trabajan en conjunto pueden compartir cierto espacio de almacenamiento compartido sobre el que leer y escribir:
- Archivos
- Memoria compartida (seguramente en una estructura de datos del kernel)
- Librerías adicionales
- Señales (solo sincronización)
En resumen, hay tres cuestiones a tratar:
- Cómo un proceso puede pasar información a otro
- Evitar interferencias: que no haya colisiones por dos procesos accediendo a lo mismo
- Garantizar un orden correcto cuando hay dependencias de lectura y escritura
También es importante mencionar que estas cuestiones también se pueden aplicar sobre los hilos. Para pasar información, la forma más sencilla es aprovechar que los hilos comparten espacios de direcciones, pero para el resto, se pueden aplican las mismas soluciones que los procesos, dado que son los mismos problemas.
Carreras críticas
Pongamos un ejemplo de una cola de impresión o spooler de impresión. Cada vez que un proceso desee imprimir un archivo, deberá introducir su dirección en un directorio de spooler. Otro proceso, el demonio de impresión, comprobará de forma periódica si hay nuevos archivos, imprimirlos y luego eliminarlos del directorio.
Supongamos que el directorio tiene muchas ranuras numeradas ($0, 1, 2 \ldots$)
que almacenan un nombre de archivo. Para implementar la cola, también son
necesarias dos variables: salida, que apunta al siguiente archivo a imprimir;
y entrada, que apunta a la siguiente ranura libre.
Pongamos ahora que entrada=7 y salida=4. De forma simultánea, los procesos
$A$ y $B$ deciden imprimir un archivo.
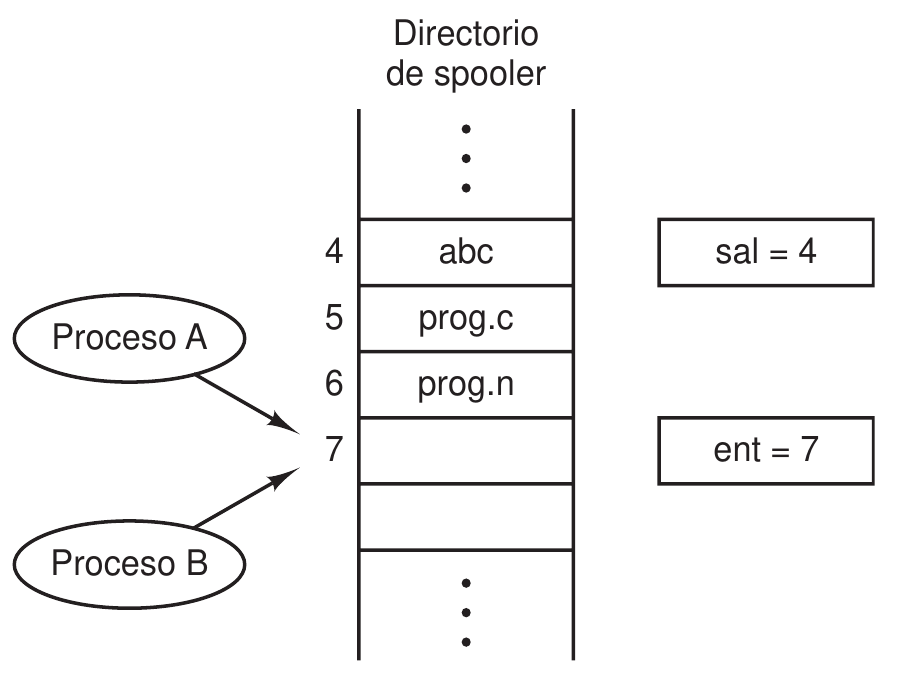
Diagrama mostrando cómo los procesos A y B desean imprimir un archivo
El código en C de ambos procesos:
buffer[entrada] = "fichero";
entrada++;
Como dictamina la Ley de Murphy, es posible que suceda lo siguiente:
- El proceso $A$ lee el valor de
entrada=7y guarda el valor en su memoria local (quizá un registro). - Justo en ese momento, se produce un cambio de contexto para que continue el proceso $B$.
- $B$ lee
entrada=7y escribe allí el nombre del archivo que quiere imprimir. - Luego $B$ actualiza
entradaa 8 y continua haciendo otras tareas. - Cuando $A$ recupere la CPU, utilizará el valor leido de antes, 7, y por tanto sobreescribirá el archivo escrito por $B$.
- Luego $A$ actualizará entrada también a 8.
Cuando el demonio de impresión vaya a enviar trabajos a la impresora, el estado del directorio es consistente, pero el archivo del proceso $B$ nunca se imprimirá.
A modo de extensión para este problema, si un código puede fallar, es que está mal programado.
Nótese que viendo el código en C es difícil determinar si se puede dar una condición crítica o no. Esto se debe ver estudiando las instrucciones máquina reales que se están ejecutando:
lw entrada, $1
lw buffer, $2
lw string, $3
;; cambio de contexto aquí
sw $3, 0($2)
addi $1, $1, 1
sw $1, 0(entrada)
Aquí ya es más evidente que, al darse al cambio de contexto, otro proceso podrá modificar los valores compartidos. Sin embargo, cuando continúe la ejecución de este proceso, se utilizarán los valores desactualizados que se habían cargado antes en registros.
Suponga el trabajo de realizar un sumatorio de números separado entre varios
procesos. Cada uno de ellos tendrá un valor inicial (ni) y un valor final
(nf). El resultado se almacenará en la variable compartida suma.
int suma = 0;
void suma(int ni, int nf) {
for (int i = ni; i <= nf; i++) {
suma += i;
}
}
Si vemos las instrucciones máquina para una iteración:
lw $1, j
lw $2, suma
;; cambio de contexto aquí
add $2, $2, $1
sw $2, suma
Se puede ver claramente que existe el mismo problema que antes.
Se puede intentar reducir las posibilidades de que ocurra una condición de carrera, pero seguimos sin solucionar el problema:
int suma = 0;
void sumar(int ni, int nf) {
int suma_parcial = 0;
for (int i = ni; i <= nf; i++) {
suma_parcial += i;
}
// problemas aquí
suma += suma_parcial;
}
Una carrera crítica o condición de carrera (race condition) sucede cuando dos o más procesos trabajan sobre recursos compartidos y el resultado depende del orden de ejecución.
Cuando la secuencia de eventos se ejecuta en un orden arbitrario, se pueden producir errores cuando dichos eventos no llegan en el orden que el programador esperaba.
El término viene porque los procesos compiten en una carrera por llegar antes que el otro, y dependiendo de quién lo haga, se pueden formar estados inconsistentes y comportamientos imprecedibles.
Todo lo que tenga un proceso compartido con otro(s) se considera un recurso.
Algunos ejemplos de recursos:
- Memoria compartida (hilos, por ejemplo)
- Ficheros
- Kernel
- …
Depurar estos programas no es nada divertido, porque las condiciones de carrera son bastante infrecuentes: en la mayoría de ejecuciones funcionará correctamente, pero en algún momento obtendremos resultados extraños y aparentemente inexplicables. Será muy difícil reproducir el problema.
Además, como hemos visto, a partir del código en C es poco evidente de qué forma puedan surgir estas situaciones.
Este problema es particularmente relevante para el kernel, porque es un recurso compartido entre todos los procesos: siempre está en memoria principal y todos ellos pueden realizar operaciones de forma concurrente realizando llamadas al sistema.
Exclusión mutua y regiones críticas
El problema del ejemplo del apartado anterior se habría solucionado si $B$ no pudiese ejecutarse en ese momento, o al menos no poder acceder al directorio de impresión. Es decir, se necesita algún mecanismo que garantice la exclusión mutua.
Sin embargo, parte del tiempo, un proceso está ocupado haciendo cálculos internos y otras cosas que no producen condiciones carrera. Solo en algunas ocasiones, donde necesita acceder a memoria compartida o archivos compartidos, podrán aparecer problemas. No sería demasiado sensato aplicarlo sobre todo, ya que se pierden los beneficios de ejecutar procesos en paralelo: es necesario definir claramente qué secciones necesitan exclusión mutua.
No existe un método que nos delimite estas regiones, solo fragmentos sospechosos.
Nótese que algunas veces puede ser difícil definir las regiones críticas con precisión, ya que el compilador reordena las instrucciones máquina resultantes. También puede causar que la regiones críticas sean más grandes.
Si se pudiesen ordenar las intrucciones de cada proceso de forma que dos procesos nunca estuviesen en sus regiones críticas al mismo tiempo, se podrían evitar las carreras.
Sin embargo, este requerimiento no es suficiente para los procesos en paralelo cooperen de forma correcta y eficiente al usar datos compartidos. Es necesario cumplir las 4 condiciones siguientes para obtener una buena solución:
- Exclusión mutua: No puede haber dos procesos operando en la región crítica.
- No puedo hacer suposiciones sobre velocidades o CPUs.
- No puede haber un proceso que sin estar en la región crítica impida que otro entre.
- Evitar inanición: No puede haber ningún proceso esperando indefinidamente para entrar en la región crítica. Se debe garantizar que podrá entrar en algún momento.
Y para mejorar el rendimiento (no es estrictamente necesario):
- No hay espera activa: el proceso deberá ceder la CPU cuando no puede entrar en la región crítica, en lugar de estar chequeando constantemente si puede entrar.
Otro problema de la espera activa es el problema de inversión de prioridades.
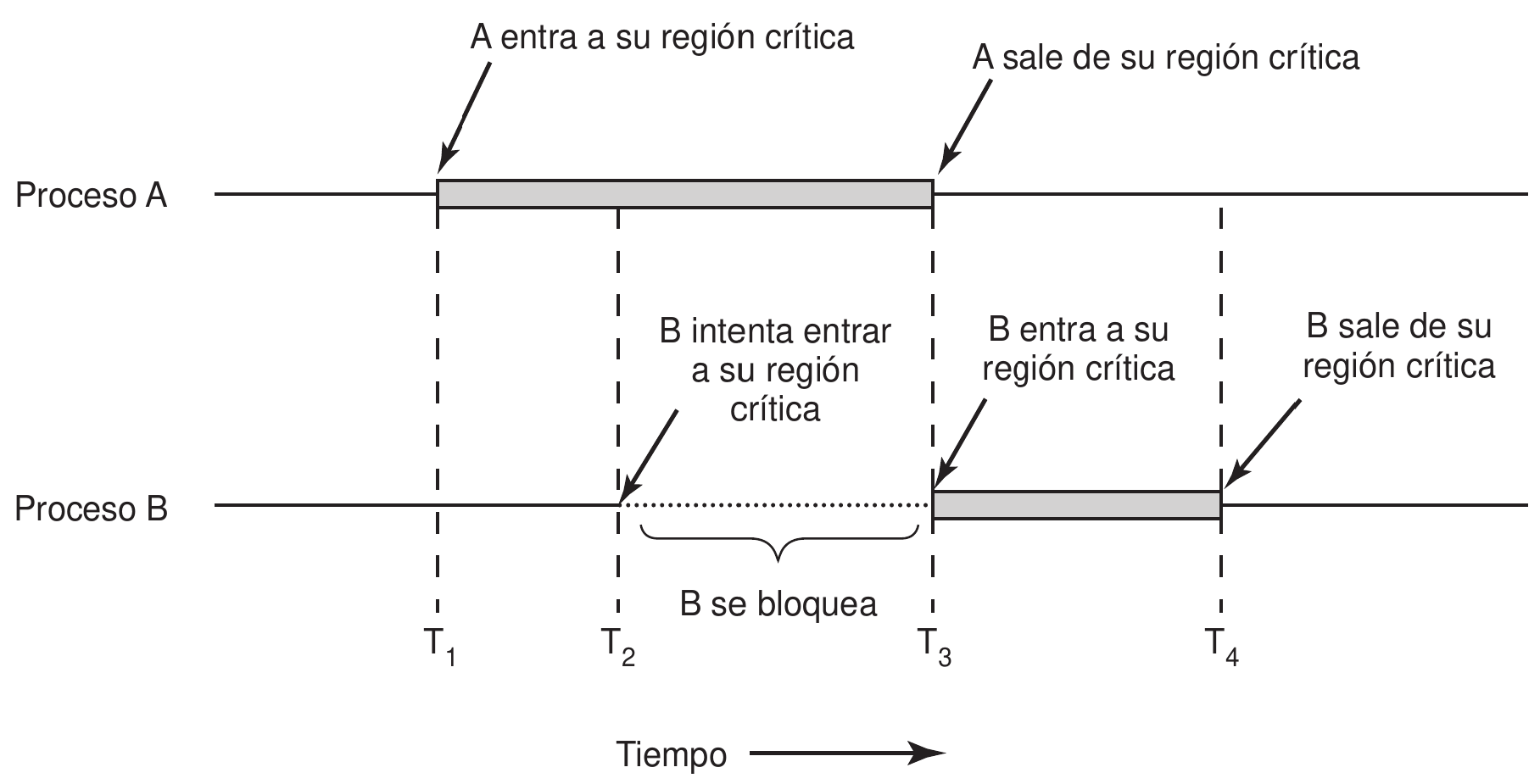
Considere un computador con dos procesos $A$ y $B$, con prioridad Alta y Baja respectivamente. Esto implica que $A$ se ejecutará siempre que esté listo.
- $B$ está en la región crítica.
- $A$ pasa al estado listo.
- Como $A$ tiene mayor prioridad, el sistema le da la CPU.
- $A$ realiza una espera activa.
Pero esta espera activa es indefinida, porque solo se detendrá cuando $B$ salga de la región crítica.
Exclusión mutua mediante el uso de regiones críticas

Diagrama mostrando el despercidio de CPU por realizar espera activa
Exclusión mutua con espera ocupada
En este apartado se discutirán varias soluciones para lograr la exclusión mutua.
Una solución sencilla es deshabilitar las interrupciones al entrar en la región crítica y volver a habilitarlas luego. Esto causa que no haya cambios de contexto por interrupciones de reloj o de cualquier otro tipo.
Es peligroso dar el poder para deshabilitar las interrupciones en modo usuario: existe la posibilidad de que nunca se vuelvan a habilitar. Un usuario malicioso podría bloquear todo el sistema con una instrucción.
Sin embargo, el kernel hace esto constantemente, para evitar que le interrumpan mientras actualiza sus datos y que quede en un estado inconsistente. La diferencia reside en que el kernel confía en sus propios códigos.
Otros problemas:
- Inútil en sistemas multicore: solo afecta al core actual, el resto de las CPUs podrán seguir accediendo a la memoria compartida sin limitaciones.
- Tampoco funciona con hilos: el cambio de contexto de hilos no involucran interrupciones, por lo que nadie impide que ambos accedan a la región crítica.
Uso de una variable compartida para determinar si es posible entrar en la región crítica:
0 -- Región crítica libre ==> Candado abierto (cierra cuando entres)
1 -- Región crítica ocupada ==> Candado cerrado
Sin embargo, esto tiene un problema fundamental: ahora acceder al candado es una región crítica. Ocurre el mismo problema de antes: si un proceso se lee el candado y se produce un cambio de contexto antes de que actualice el candado, es posible tener dos procesos en la región crítica. Recuerde que queremos garantizar que siempre se produzca la exclusión mutua.
while (TRUE) {
while (turno != TURNO_ESTE_PROCESO); // espera activa
region_critica();
turno = (turno+1) % TOTAL_TURNOS;
region_nocritica();
}
Hay una variable de turno compartida, que dictamina qué proceso puede acceder: si el turno coincide con el que tiene el proceso, este puede entrar. Cuando salga de la región crítica, se pasa el turno al siguiente.
Hay que tener cuidado para que varios procesos no tengan asignado el mismo turno.
- No cumple la condición 3: es posible que no haya nadie en la región crítica, pero un proceso no pueda entrar por no tener el turno.
- Problema de rendimiento: se va a la velocidad del más lento. Si
region_nocritica()en un proceso lleva mucho tiempo, el otro proceso deberá esperar a que termine y cambie el turno (aunque no entre en la región crítica). - Espera activa: cuando el proceso intenta entrar, está comprobando constantemente si tiene el turno.
A partir de aquí, se discuten buenas soluciones que cumplen las 4 primeras condiciones.
int turno;
int interesado[N];
void entrar_region(int proceso) {
int otro = 1 - proceso;
// IMPORTANTE: deja de funcionar si se intercambian estas dos líneas.
interesado[proceso] = TRUE;
turno = proceso;
while (turno == proceso && interesado[otro] == TRUE);
}
void salir_region(int proceso) {
interesado[proceso] = FALSE;
}
Componentes
entrar_region: se debe llamar con el número del proceso. Hará una espera activa hasta que sea seguro entrar.salir_region: libera la región crítica.turno: no indica a quién le toca.interesados: array de booleanos, si esTRUEes que ese proceso también quiere entrar en la región crítica.
Este código solo funciona para dos procesos, para hacerlo genérico hay que hacer algún cambio algo más complejo.
Funcionamiento
- Primero calculo el ID del otro proceso.
- Digo que yo estoy interesado.
- Luego me asigno el turno.
Ahora hay 2 posibilidades:
- 1 interesado:
interesado[otro]es falso, por tanto entra a la región crítica. - 2 interesados:
- El proceso que escribió primero en turno:
turno == procesoes falso, porque el otro proceso lo ha sobreescrito. Este entra en la región crítica. - El proceso que escribió después:
turno == procesoes verdadero yinteresado[otro]también, por tanto realiza una espera activa. Esto se realizará hasta que otro diga que no está interesado (cuando salga).
- El proceso que escribió primero en turno:
Nótese que hay una carrera crítica sobre la variable turno, pero está
completamente controlada.
Características
- Cumple las cuatro primeras condiciones.
- También funciona para sistemas multicore si se garantiza la coherencia caché:
la variable
turnodebe tener un valor coherente en todas las CPUs.
Para utilizar esta solución, se necesita ayuda por parte del Sistema Operativo y/o Hardware.
tsl reg, LOCK
La instrucción TSL (Test and Set Lock) lee el contenido de la palabra de
memoria LOCK y lo guarda en el registro reg. Después almacena un valor
distinto de 0 en esa misma dirección. Puede ser muy lenta: fallos caché, fallos
de página…
Se debe garantizar la atomicidad: realizar ambas acciones tienen que completarse sin que ningún otro procesador acceda a esa memoria.
Todos los lenguajes máquina tienen una instrucción para esto, o alguna equivalente.
Opciones de implementación
- Deshabilitar interrupciones: no funciona para multicore.
- Bloquear el bus de memoria: ningún otro procesador más puede hacer lecturas o escrituras en memoria.
Ejemplo de uso
entrar_region:
tsl reg, LOCK ;; Copiar el LOCK a reg y ponerlo a 1
cmp reg, 0 ;; ¿Era LOCK == 0?
jne entrar_region ;; Si no, loop (espera activa)
ret ;; Volver => Entrar región
salir_region:
mov LOCK, 0 ;; poner a 0 el lock
ret
Nótese que para salir de la región no es necesario usar TLS: ya está dentro de la región crítica, por lo que nadie interfiere con él.
XCHGTodas las CPUs Intel x86 utilizan la instrucción XCHG de forma alternativa
a la instrucción TSL. Esta intercambia el contenido de dos ubicaciones de
forma atómica.
El código equivalente al anterior con esta instrucción es:
entrar_region:
mov reg, 1 ;; Coloca 1 en el registro
xchg reg, LOCK ;; Intercambia el registro y LOCK
cmp reg, 0 ;; ¿Era LOCK == 0?
jne entrar_region ;; Si no, loop (espera activa)
ret ;; Volver => Entrar región
salir_region:
mov LOCK, 0 ;; poner a 0 el lock
ret
Las 2 soluciones anteriores funcionan correctamente, con el defecto de que necesitan espera activa.
Con las funciones siguientes se puede evitar la espera activa y resolver el problema de inversión de prioridades.
sleep: llamada al sistema que autobloquea el proceso hasta que otro lo despierte.wakeup: llamada al sistema que despierta un proceso autobloqueado.
La llamada wakeup recibe como parámetro el proceso que debe despertar. De
forma alternativa, tanto sleep como wakeup podrán recibir como parámetro una
dirección de memoria para asociar las llamadas entre sí.
Hay que tener cuidado con ejecutar wakeup antes del sleep, porque se quedará
bloqueado de forma indefinida.
El problema del productor-consumidor
Se tienen dos procesos que operan sobre un buffer compartido:
- Productor: coloca información en el buffer.
- Consumidor: retira esa información y la procesa.
Se puede generalizar a $n$ productores y $n$ consumidores, pero empezaremos por algo simple.

Diagrama del problema Productor-Consumidor.
El buffer compartido es una pila FIFO (First In, First Out), por lo que se
necesita una variable cuenta que indica la última posición. También es posible
utilizar una cola LIFO.
Los problemas aparecen cuando el productor desea insertar un nuevo elemento pero el buffer está lleno, o cuando el consumidor desea extraer algo y este está vacío. Cuando ocurra eso, lo mejor es enviar el proceso a dormir y hacer que el otro lo despierte cuando pueda continuar su trabajo.
De esta forma evitamos las esperas activas, pero no se solucionan las
carreras críticas: el acceso a cuenta no está restringido.
- Supongamos que inicialmente el buffer está vacío y comienza ejecutándose el consumidor.
- El consumidor lee el valor de
cuenta, que es 0. - Antes de que pueda hacer el
sleep, se produce un cambio de contexto al productor. - El productor inserta el ítem y realiza el
wakeup(consumidor). Como el consumidor nunca realizó susleep, esta llamada se pierde. - Cuando el consumidor recupere la CPU, ejecutará
sleepautobloqueándose. - Ahora debe continuar el productor, que seguirá insertando ítems hasta que el
buffer se llene y entonces realizará su
sleep.
Como ya el productor realizó un wakeup, no lo volverá a hacer (cuenta no
volverá a ser 1) y ambos procesos quedarán bloqueados de forma indefinida.
#define N 100
int buffer[N];
int cuenta = 0;
void productor() {
while (TRUE) {
int item = producir_item();
// Si está lleno, no puedo producir.
// Me duermo hasta que haya elementos.
if (count == N)
sleep();
// Región crítica
insertar_item(item);
cuenta++;
// Si acabo de añadir el primer item,
// despertar al consumidor
if (count == 1)
wakeup(consumidor);
}
}
void consumidor() {
while (TRUE) {
// Si no hay elementos que consumir,
// no puedo continuar. Me duermo.
if (cuenta == 0)
sleep();
// Región crítica
int item = extraer_item();
cuenta--;
// Si acabo de consumir el último item,
// despertar al productor.
if (cuenta == N-1)
wakeup(productor);
consumir_item(item);
}
}
Las funciones utilizadas:
productor: función principal del proceso productor.consumidor: función principal del proceso consumidor.producir_item: genera y devuelve un nuevo item a insertar.insertar_item: inserta el item en la posicióncuentadel buffer compartido.extraer_item: devuelve el ítem en la posicióncuenta-1.consumir_item: toma un item y realiza su procesamiento.
Semáforos
Se trata de una variable entera positiva almacenada en el kernel, por lo que está compartida entre todos los procesos.
Funciones asociadas:
down: lee el valor del semáforo:- si es 0, se autobloquea realizando un
sleep. - si no, resta 1 al semáforo.
- si es 0, se autobloquea realizando un
up: suma 1 al semáforo. Si hay algún proceso autobloqueado por realizar un down, se desbloquea a uno de ellos al azar para que termine de ejecutar sudown.
Cada una de estas operaciones deben de ser atómicas: ningún otro proceso podrá acceder al semáforo hasta que la operación se haya completado o el proceso bloqueado. Es absolutamente esencial esta característica para evitar carreras críticas y otros problemas de sincronización. Seguramente encontremos la instrucción TSL en su implementación.
El programa no puede hacer suposiciones sobre qué proceso se va a despertar una
llamada up.
También hay llamadas al sistema para crear y destruir semáforos. Es importante borrarlos explícitamente, sino seguirán el en kernel hasta que se apage el computador. Y al volver a ejecutar el programa, usará el valor ya existente, por lo que se puede dar comportamientos inesperados.
Recuerde es posible leer y escribir el valor del semáforo directamente, sin utilizar esta librería de funciones. Sin embargo, se pierde su uso: no estará protegido contra carreras críticas.
Nótese también que down y up son generalizaciones de sleep y wakeup.
A modo de ejemplo, resolvamos el problema del productor-consumidor con semáforos. Para ello necesitamos tres:
lleno: lleva la cuenta de cúantos elementos hay en el buffer.vacio: lleva la cuenta de cúantos huecos hay en el buffer.mutex: se trata de un semáforo binario. Se utilizará a modo de candado para la exclusión mutua (MUTual EXclusion) de la región crítica, 0 para candado cerrado (región crítica ocupada) y 1 para candado abierto (región crítica libre).
Los dos primeros se utilizarán por la funcionalidad de sleep y wakeup para
la sincronización de los procesos: cuando el buffer esté lleno, vacio será 0,
por lo que al hacer un down(&vacio), el productor se bloqueará hasta que haya
un hueco. Lo mismo sucede para lleno.
Esta solución funciona perfectamente porque los semáforos resuelven el problema
de que se pierdan wakeups.
#define N 100
int buffer[N];
int cuenta = 0;
semaforo lleno = 0; // num de elementos en el buffer
semaforo vacio = N; // num huecos en el buffer
semaforo mutex = 1; // controla el acceso a la región crítica
void productor() {
while (TRUE) {
int item = generar_item();
// Me bloqueo si el buffer esta lleno.
down(&vacio);
// Entrar a la región crítica.
// - 0: región crítica ocupada, me bloqueo.
// - 1: región crítica libre, sigo.
down(&mutex);
insertar_item(item);
cuenta++;
// Salgo de la región crítica, despierto al
// consumidor por si quería entrar.
up(&mutex);
// Despierto al consumidor por si estaba
// el buffer vacío.
up(&lleno);
}
}
void consumidor() {
while (TRUE) {
// Me bloqueo si el buffer esta vacio.
down(&lleno);
// Entro en la región crítica como antes.
down(&mutex);
int item = extraer_item();
cuenta--;
// Salgo de la región crítica.
up(&mutex);
// Despierto al productor por si estaba
// el buffer lleno.
up(&vacias);
consumir_item(item);
}
}
#include <semaphore.h>
// Abre un semáforo nuevo o ya existente
sem_t* sem_open(const char* name, int oflag);
sem_t* sem_open(const char* name, int oflag, mode_t mode, unsigned int value);
// Cierra el semáforo en el proceso actual
sem_t* sem_close(sem_t* sem);
// Borra los semáforos del kernel
int sem_unlink(const char* name);
// Operación DOWN
int sem_wait(sem_t* sem);
// Operación DOWN, en lugar de bloquearse, lanza el error EAGAIN
int sem_trywait(sem_t* sem);
// Operación UP
int sem_post(sem_t* sem);
- El semáforo se identifica con un nombre.
oflag: constantes definidas enfcntl.h.mode: permisos de creación del semáforo, habitualmente0700.value: valor inicial del semáforo.- En error, las funciones devuelven -1 (o
SEM_FAILED) explicando el error enerrno.
Mutexes
Cuando no se necesita la habilidad de un semáforo de contar, habitualmente se implementa una versión simplificada, el mutex. Se implementan con facilidad y eficiencia, lo que hace que sean especialmente útiles para la administración de una región crítica y garantizar la exclusión mutua.
Variable que puede estar en dos estados: abierto o cerrado.
mutex_unlock: abre el candado.mutex_lock: si está abierto, la función regresa. De lo contrario espera.mutex_trylock: si está abierto se procede como antes, pero si está cerrado se devuelve un error. De esta forma, se puede seguir trabajando en otra tarea mientras no se pueda acceder a la región crítica.
Si se bloquean varios por el mutex, se selecciona uno al azar para que continue.
Se llama a mutex_lock cuando un proceso o hilo necesita acceder a una región
crítica, y a mutex_unlock para indicar que ha terminado con ella. Recuerde que
estas operaciones deben ser atómicas.
Esta idea es bastante simple, por lo que son bastante sencillos de implementar
cuando hay disponible una instrucción como tsl o xchg.
mutex_lock:
tsl reg, MUTEX ;; Copiar MUTEX a reg y poner MUTEX a 1
cmp reg, 0 ;; return si reg == 0
jze ok
call thread_yield ;; sino, ceder la CPU
jmp mutex_lock ;; volver a probar cuando regrese
ok: ret
mutex_unlock:
move MUTEX, 0 ;; Poner MUTEX a 0 (abierto)
ret
Con hilos, todo esto se puede implementar en el espacio de usuario, lo que no
requiere llamadas al kernel. Como consecuencia, realizar un mutex_lock es muy
rápido.
Nótese la diferencia con el código del ejemplo de uso de la instrucción TSL:
cuando no se puede entrar en la región crítica se hace una llamada
a thread_yield para dejar la CPU libre, esencialmente realizando una espera
activa cediendo la CPU. En una implementación más realista, se debería marcar
como bloqueado. Cuando se opera con hilos en espacio de usuario esto es casi
obligatorio: no hay un reloj que genere cambios de contexto, por lo que la
espera activa de un hilo será indefinida.
#include <pthread.h> // Compilar con -lpthreads
int pthread_mutex_init(pthread_mutex_t* mutex);
// Solo se puede destruir si está abierto
int pthread_mutex_destroy(pthread_mutex_t* mutex);
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
En éxito, estas funciones devuelven 0, sino dan un código de error.
En pthread_mutex_trylock se devuelve 0 si adquirió el mutex.
Si hay una condición para entrar en la región crítica, esta debe comprobarse también una vez dentro:
if (condicion) { // posible cambio de contexto aquí, // que haga la condición falsa if (trylock(&mutex) == 0) { if (condición) { // región crítica } unlock(&mutex) } }
Variables de condición
Permite bloquear y despertar procesos o hilos según se cumpla o no una condición.
Están asociadas a un mutex: solo tiene sentido usarlas en una región crítica. Por tanto, el código debe tener esta forma:
pthread_mutex_lock(&mutex);
while (condición) {
pthread_cond_wait(&cond, &mutex);
}
// ~~~ Región crítica ~~~
pthread_cond_signal(&cond, &mutex);
pthread_mutex_unlock(&mutex);
#include <pthreads.h> // Compilar con -lpthreads
int pthread_cond_init(pthread_cond_t* cond, const pthread_condattr_t* attr);
int pthread_cond_destroy(pthread_cond_t* cond);
Funciones de creación y borrado de variables de condición. El parámetro attr
permite pasar más opciones opciones de creación, pero se puede dejar a NULL.
Recuerde que borrar una variable de condición cuando hay hilos bloqueados es
undefined behaviour.
Es importante recalcar que estas funciones devuelven un código de error en caso de que algo vaya mal, de lo contrario devuelven 0.
int pthread_cond_wait(pthread_cond_t* cond, pthread_mutex_t* mutex);
Esta función bloquea el hilo actual y libera el mutex de forma atómica. Es importante que el mutex esté cerrado, sino se dará undefined behaviour.
El hilo se desbloqueará cuando otro lo avise, pero hay que tener en cuenta que cuando se bloqueó seguía en la región crítica. Esto podría causar problemas si dos hilos se despiertan y continuan: ¡nos hemos cargado la exclusión mutua!
Por eso, cuando esta función termine, se debe haber adquerido el mutex para poder continuar.
Como esta función cierra y abre el mutex, es necesario pasarlo por parámetro. En lugar de especificarlo en la hora de creación, es mejor realizarlo en la propia función por si hay mutexes anidados.
int pthread_cond_signal(pthread_cond_t* cond);
int pthread_cond_broadcast(pthread_cond_t* cond);
La función signal avisa a un único hilo bloqueado por wait escogido
aleatoriamente para que se desbloquee. Como ambos hilos están dentro de la
región crítica, se debe volver a evaluar el mutex, y es imposible predecir quién
continuará.
Como consecuencia, el código no puede asumir que un hilo u otro continuará con la ejecución. Por ese motivo, es mejor usar estas funciones al final de la región crítica.
Si se lanza un signal pero no hay nadie bloqueado, esta llamada se perderá.
Por otro lado, broadcast despierta a todos los hilos que estén bloqueados por
esta variable de condición. Como antes, solo uno de ellos podrá readquerir el
mutex y continuar, pero no están bloqueados esperando por el signal.
En la siguiente figura se muestra el funcionamiento de las variables de condición y mutexes:
- El hilo de la izquierda realiza un
lockdel mutex y entra en la región crítica. - Un poco después, el hilo de la derecha desea hacer lo mismo, pero debe bloquearse. Se queda esperando a que se libere la región crítica.
- Luego, el hilo de la izquierda realiza un
wait, lo que implica liberar el mutex. Este se autobloquea hasta que reciba unsignal. - Como la región crítica está libre, ahora el hilo de la derecha puede entrar.
- Este realiza la llamada a
signalpara despertar al hilo de la izquierda. - El hilo de la izquierda se vuelve a bloquear porque necesita acceso a la región crítica: espera a que se libere el mutex.
- El hilo de la derecha sale de la región crítica, por lo que ahora el hilo de la izquierda puede continuar.
Fíjese en que en el hilo de la izquierda, se espera por dos motivos completamente diferentes. Entender eso es clave para comprender el funcionamiento de las variables de condición.

Diagrama del funcionamiento de mutexes y variables condición.
A modo de ejemplo, resolvamos como antes el problema del productor-consumidor en varios hilos utilizando mutexes y variables de condición:
#include <pthread.h>
#define NUM_ITEMS 10000
#define N 100
int buffer[N];
int cuenta = 0;
pthread_mutex_t mutex; // Mutex que controla el acceso a la región crítica
pthread_condc_t cond_cons; // Para bloquear el consumidor si el buffer está vacío
pthread_condc_t cond_prod; // Para bloquear el productor si el buffer está lleno
void* productor(void* param) {
for (int i = 0; i < NUM_ITEMS; i++) {
int item = generar_item();
pthread_mutex_lock(&mutex);
while (cuenta >= N) {
pthread_cond_wait(&cond_prod, &mutex);
}
insertar_item(item);
cuenta++;
pthread_cond_signal(&cond_cons, &mutex);
pthread_mutex_unlock(&mutex);
}
pthread_exit(0);
}
void* consumidor(void* param) {
for (int i = 0; i < NUM_ITEMS; i++) {
pthread_mutex_lock(&mutex);
while (cuenta <= 0) {
pthread_cond_wait(&cond_cons, &mutex);
}
int item = extraer_item();
cuenta--;
pthread_cond_signal(&cond_prod, &mutex);
pthread_mutex_unlock(&mutex);
consumir_item(item);
}
pthread_exit(0);
}
Monitores
Los ejemplos que se han discutido aquí son bastante sencillos, pero en programas más grandes deja de ser tan claro y un pequeño error puede causar grandes estragos.
Estructura de alto nivel que contiene datos y funciones. Los procesos pueden llamar a los procedimientos almacenados, pero no a los datos directamente.
Cuando se llama a una función se hace un mutex_lock y cuando devuelve un
mutex_unlock.
Se trata de un concepto del lenguaje (recuerda a una Clase de la
Programación Orientada a Objetos), y C no los tiene. El compilador debe estar al
tanto de su existencia para poder incluir los bloqueos y desbloqueos de los
mutexes o semáforos binarios. Un ejemplo de un lenguaje que soporta los
monitores es Java: con la palabra clave syncronized el método se ejecutará de
forma exclusiva.
Esta estructura es conceptualmente igual que un mutex, con la ventaja de que da muchos menos errores de programación debido a que el compilador inserta los bloqueos automáticamente.
Como desventaja es que los monitores están diseñados para gestionar memoria compartida. En sistemas distribuidos de varias CPUs, cada uno con su propia memoria y conectadas a través de una red estas primitivas no see pueden utilizar.
Para usar variables de condición en Java se usan los métodos de la clase
Object: wait y notify.
// Clase principal
class ProductorConsumidor {
public static void main(String[] args) {
Monitor m = new Monitor(100);
Productor p = new Productor(m);
Consumidor c = new Consumidor(m);
p.start();
c.start();
}
}
// Código del Productor
class Productor extends Thread {
private final Monitor m;
public Productor(Monitor m) {
this.m = m;
}
// Función principal del hilo
public void run() {
while (true) {
int item = producir_item();
m.insertar_item(item);
}
}
private int producir_item() {
// ...
}
}
// Código del Consumidor
class Consumidor extends Thread {
private final Monitor m;
public Consumidor(Monitor m) {
this.m = m;
}
// Función principal del hilo
public void run() {
while (true) {
int item = m.extraer_item();
consumir_item(item);
}
}
private void consumir_item(int item) {
// ...
}
}
// Clase Monitor
class Monitor {
// Datos compartidos
private int buffer[];
private int cuenta;
private final int N;
public Monitor(int N) {
this.N = N;
buffer = new int[N];
int cuenta = 0;
}
// Esto se ejecuta en de forma exclusiva
public synchronized void insertar_item(int item) {
if (cuenta == N)
inactivo();
buffer[cuenta] = item;
cuenta++;
if (cuenta == 1)
notify();
}
// Esto se ejecuta en de forma exclusiva
public synchronized int extraer_item() {
if (cuenta == 0)
inactivo();
cuenta--;
int item = buffer[cuenta];
if (cuenta == N-1)
notify();
return item;
}
private void inactivo() {
try {
wait();
} catch (InterruptedException e) {
}
}
}
Paso de mensajes
Hasta ahora se han tratado con recursos compartidos (principalmente memoria). En la práctica, es posible que dos procesos no puedan compartir memoria por no estar en el mismo computador. Pero gracias al paso de mensajes, es posible utilizar la red para resolver problemas como el del Productor-Consumidor.
Se hace uso de las siguientes primitivas:
send: envía un mensaje a un destino especificado.receive: recibe un mensaje de un origen concreto o cualquiera. Si no hay un mensaje, el proceso se puede bloquear.
Es una relación 1:1, cada send tiene su receive.
Problemas:
- Mensajes perdidos: enviar de vuelta un acuse de recibo o acknowledgement.
- Acuses de recibo perdidos: numerar cada mensaje, y descartar aquellos que tengan el mismo número.
- Autenticación: ¿cómo saber que no me estoy comunicando con un impostor?
- Eficiencia (dentro del mismo computador): es difícil que sea más rápido que usar un semáforo y escribir en memoria. Se ha investigado mucho acerca de esto.

Funcionamiento de send() y receive()
Como siempre, veamos el como resolver el problema del productor-consumidor con paso de mensajes sin usar memoria compartida. Esta solución emplea un total de $N$ mensajes.
- El consumidor envía $N$ mensajes vacios al productor a modo de petición.
- Cada vez que el productor reciba un mensaje vacío, enviará uno lleno.
- A continuación, el consumidor recibe un elemento del productor.
- Luego el consumidor enviará otro mensaje vacío.
#define N 100
void productor() {
while (TRUE) {
int item = generar_item();
// Esperar a una peticion (mensaje vacio)
mensaje m;
receive(consumidor, &m);
crear_mensaje(&m, item);
send(consumidor, &m);
}
}
void consumidor() {
mensaje m;
for (int i = 0; i < N; i++)
send(productor, &m); // N mensajes vacios
while (TRUE) {
receive(productor, &m);
// Extraer el item del mensaje
int item = extraer_item(&m);
// Enviar la peticion de vuelta
limpiar(&m)
send(produtor, &m);
consumir_item(item);
}
}
Al igual que en apartados anteriores, cuando se intenta enviar un mensaje a un buzón lleno, el proceso se suspende. Lo mismo cuando se intenta recibir de un buzón vacío.
Para el problema del productor-consumidor, esto permite eliminar completamente los buffers que nosotros habíamos creado.
- MPI (Message Passing Interface): se trata de una librería estándar muy importante que es mantenida por un comité. Se utiliza mucho en la computación científica, sobre todo para supercomputadores.
- OpenMP: Otra librería que permite abstraer los pthreads, principalmente para simplificar el uso de hilos.
Barreras de sincronización
Se utiliza solo para sincronizar procesos y hacer que vayan al mismo ritmo. Esto es particularmente útil para la resolución de problemas científicos o de ingeniería. Suelen tener el siguiente formato, por ejemplo, una computación para la predicción meteorológica:
// Iteración del algoritmo
for (t = 0; t < tmax; t++) {
// Computación por cada dimensión espacial
for (x ...)
for (y ...)
for (z ...) {
// Cálculos complejos
}
barrera();
}
En la siguiente figura:
- Los procesos realizan su cálculo antes de llegar a la barrera.
- Todos menos $C$ han llegado a la barrera, por lo que quedan a la espera.
- Una vez que $C$ llega a la barrera, todos pueden continuar.
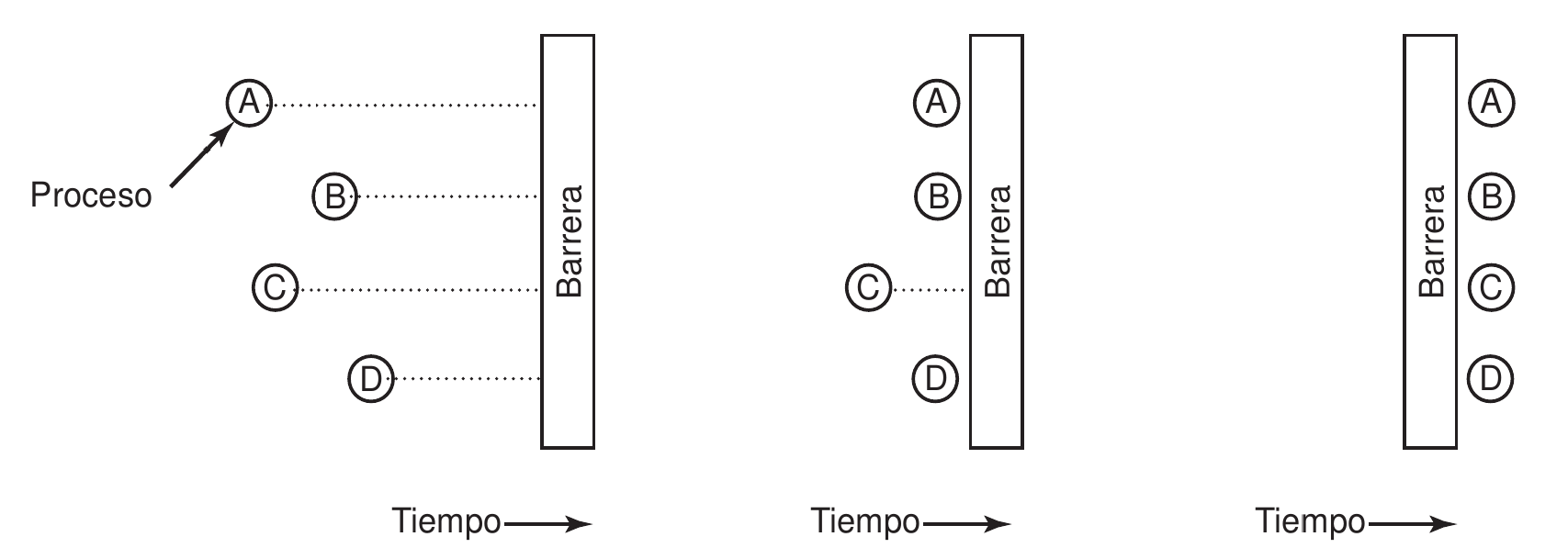
Ejemplo de uso de una barrera
Problemas clásicos
A la hora de presentar nuevas soluciones para comunicar y sincronizar procesos, habitualmente se ponen a prueba con alguno de estos problemas. De esta forma se pueden comparar de forma sencilla y ver las ventajas y desventajas de cada uno. Hasta el momento hemos discutido el problema del Productor-Consumidor, pero también existen otros.
Nosotros podemos usar estos problemas para comprender mejor el uso de las primitivas planteadas en este artículo.
El problema de los filósofos hambrientos
Cinco filósofos están sentados en una mesa circular, cada uno con su plato. Entre cada plato hay un tenedor.
- La vida de un filósofo se basa en periodos alternos entre comer y pensar.
- Cuando un filósofo tenga hambre, deberá coger su tenedor izquierdo y derecho para poder comer.
¿Cuál es el procedimiento de un filósofo para que pueda comer y pensar?
La solución obvia es la siguiente:
#define N 5 // número de filósofos
// i es el número del filósofo
void filosofo(int i) {
while (true) {
pensar();
tomar_tenedor(i);
tomar_tenedor((i+1) % N);
comer();
poner_tenedor(i);
poner_tenedor((i+1) % N);
}
}
Pero esta solución está mal: ¿qué sucede si todos los filósofos tienen hambre y desean comer? Tomarán todos a la vez su tenedor izquierdo, pero ninguno de ellos podrá continuar. Este es un caso de interbloqueo: nadie podrá progresar y los filófosos morirán de hambre (inanición).
Si los filósofos esperan un tiempo aleatorio es cierto que se reduciría la probabilidad de interbloqueo, pero eso no soluciona totalmente el problema.
La solución correcta sin interbloqueos y máximo paralelismo es la siguiente:
// Por conveniencia
#define N 5
#define IZQ (i + N-1) % N
#define DER (i + 1) % N
// Estado del filósofo
#define PENSANDO 0 // El filósofo piensa
#define HAMBRIENTO 1 // El filósofo quiere comer
#define COMIENDO 2 // El filósofo come
int estado[N]; // Estados de los N filósofos
semaforo s[N]; // Se usa para bloquear a cada filósofo
semaforo mutex = 1;
void filosofo(int i) {
while (TRUE) {
pensar();
tomar_tenedores(i);
comer();
poner_tenedores(i);
}
}
void tomar_tenedores(int i) {
// Entrar en región crítica:
// acceder al estado de forma exclusiva
down(&mutex);
// Cambiar el estado
estado[i] = HAMBRIENTO;
// Trata de adquirir los 2 tenedores
probar(i);
// Salir de región crítica
up(&mutex);
// Bloquear si no se consiguieron los tenedores
down(&s[i]);
}
void poner_tenedores(int i) {
down(&mutex);
estado[i] = PENSANDO;
// Acabo de dejar los tenedores:
// ¿pueden mis compañeros comer ahora?
probar(IZQ);
probar(DER);
up(&mutex);
}
void probar(int i) {
int hambriento = estado[i] == HAMBRIENTO;
int izq_no_come = estado[IZQ] != COMIENDO;
int der_no_come = estado[DER] != COMIENDO;
if (hambriento && izq_no_come && der_no_come) {
estado[i] = COMIENDO;
// Estoy comiendo, por tanto no me bloqueo cuando vuelva
// a tomar_tenedores
up(&s[i]);
}
}
El problema de los lectores y escritores
Imagine un sistema de reserva de una aerolínea, con muchos procesos en competición que desean leer y escribir en la Base de Datos.
Los lectores pueden acceder de forma simultánea al mismo dato sin problemas, pero un escritor debe tener acceso exclusivo.
¿Cómo se programan los lectores y escritores?
semaforo mutex = 1; // controla el acceso a num_lectores
semaforo bd = 1; // controla el acceso a la BD
int num_lectores = 0; // Núm de procesos que leen o quieren leer
void lector() {
while (TRUE) {
down(&mutex);
num_lectores++;
// Si es el primer lector, bloquea la BD contra escrituras
if (num_lectores == 1)
down(&bd);
up(&mutex);
leer_bd();
down(&mutex);
num_lectores--;
// Si es el ultimo lector, liberar la BD para escrituras
if (num_lectores == 0)
up(&bd);
up(&mutex);
usar_datos_leidos();
}
}
void escritor() {
while (TRUE) {
pensar_datos();
down(&bd);
escribir_bd();
up(&bd);
}
}
El mayor peligro de este problema es la inanición: si el escritor espera a que todos los lectores terminen para actualizar un dato, es muy probable que nunca pueda llegar a hacerlo. Esta solución sobre de esto.
Un posible apaño sería evitar añadir nuevos lectores si hay un escritor que desee terminar su trabajo.