Introducción
En el pasado se experimentó un gran aumento del rendimiento de los microprocesadores gracias a mejoras de la tecnología. Sin embargo, hoy en día no se puede mantener este ritmo por limitaciones físicas (efecto de túnel) y la disipación del calor. Como consecuencia, en lugar de intentar hacer los procesadores más rápidos, actualmente se están introduciendo muchos de ellos en un mismo chip para poder realizar tareas en paralelo. Como es lógico, el Sistema Operativo debe de estar al corriente de esto.
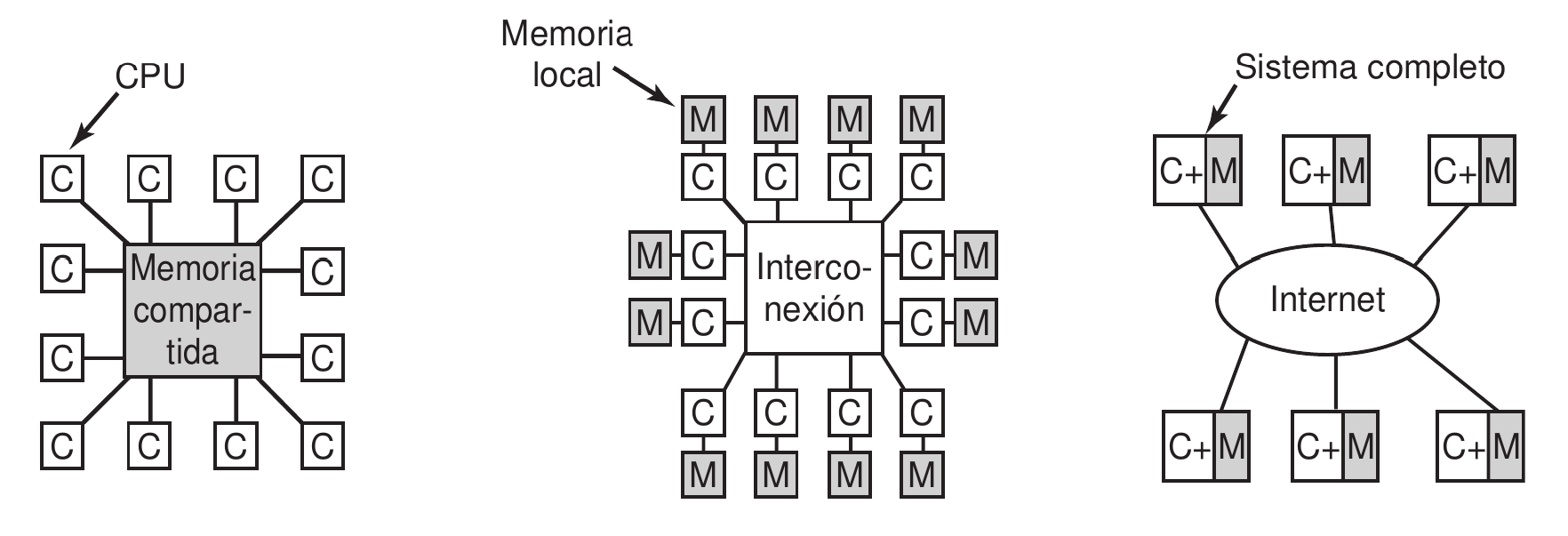
Varios tipos de arquitecturas
| Multiprocesador | Uso de una única memoria compartida con varios procesadores que utilizan para comunicarse. Lo más eficiente en esta arquitectura son los hilos (OpenMP).
Estos sistemas son difíciles de construir y escalar. Sin embargo son sencillos de programar. |
| Multicomputador | Cada procesador tiene su propia memoria privada. Para comunicarse con el resto de procesadores se utiliza una rápida red de interconexión. Se utiliza paso de mensajes. Estos sistemas son más fáciles de construir, pero mucho más difíciles de programar. |
| Sistema distribuido de área amplia | Es un subtipo de multicomputador: muchos computadores en distintas localizaciones (con memorias separadas) interconectadas por Internet. Dado que esta red puede llegar a ser bastante lenta, obliga a que sea un sistema débilmente acoplado. Se han hecho muchos intentos para poder «compartir memoria» en estos sistemas sin demasiado éxito (poco eficientes). |
En la práctica pueden aparecer mezclas de estos últimos. Por ejemplo, en los supercomputadores actuales:
- Nodo: memoria compartida con varios procesadores asociados.
- Red de interconexión: cada nodo está interconectado con otros mediante una rápida red de interconexión.
Dentro de un nodo se puede programar hilos, pero para comunicarse hacia afuera del mismo, se utiliza paso de mensajes.
Multiprocesadores
Cada CPU puede direccionar toda la memoria disponible, sin embargo lo pueden hacer con diferentes velocidades:
- UMA: el acceso a memoria principal es más o menos constante para todos los procesadores.
- NUMA: el acceso a memoria principal no es uniforme, es más rápido leer de determinadas regiones que de otras.
UMA
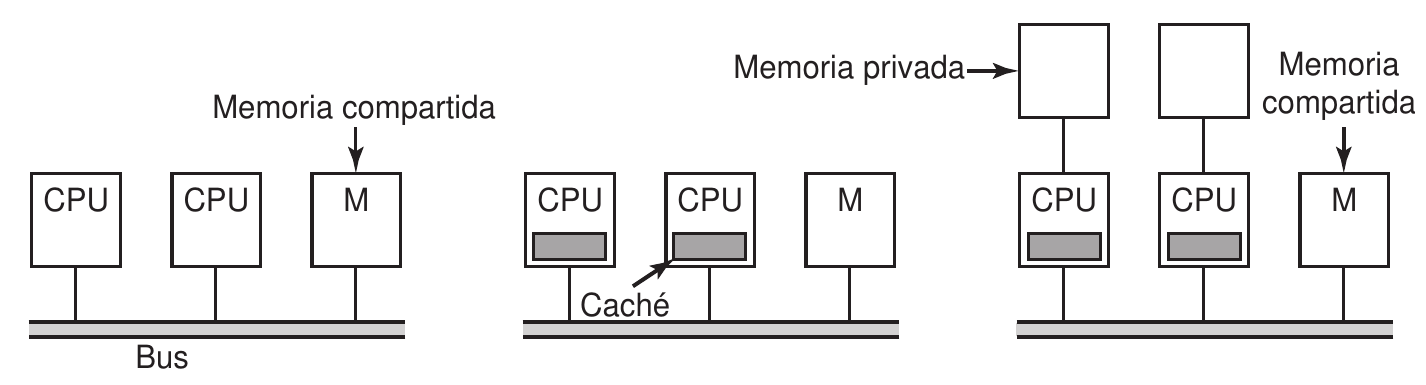
Arquitecturas UMA basadas en bus
La idea más sencilla es hacer uso de un único bus para acceder a memoria de forma uniforme. El procedimiento es el siguiente:
- Se comprueba si el bus está ocupado. En ese caso hay que esperar.
- La CPU coloca la dirección que desea y activa unas señales de control para determinar la operación.
- Espera hasta que el bus devuelva el resultado de memoria.
La espera que se experimenta en el paso 1 es el mayor problema de esta arquitectura: un único bus es un gran cuello de botella. Por ese motivo (entre otros), se ideó la jerarquía de memoria.
Sin embargo, será necesario mantener la coherencia entre las diferentes cachés: si se escribe en una de ellas, el dato se debe reflejar en el resto de cachés. De lo contrario, los datos serán inconsistentes. Para ello se emplean los protocolos de coherencia caché:
- Snooping: las otras CPUs vigilan el bus para ver si se están haciendo cambios a datos que tengan en sus cachés. En ese caso invalidarán su copia. Protocolos MSI y MESI.
- Directorio
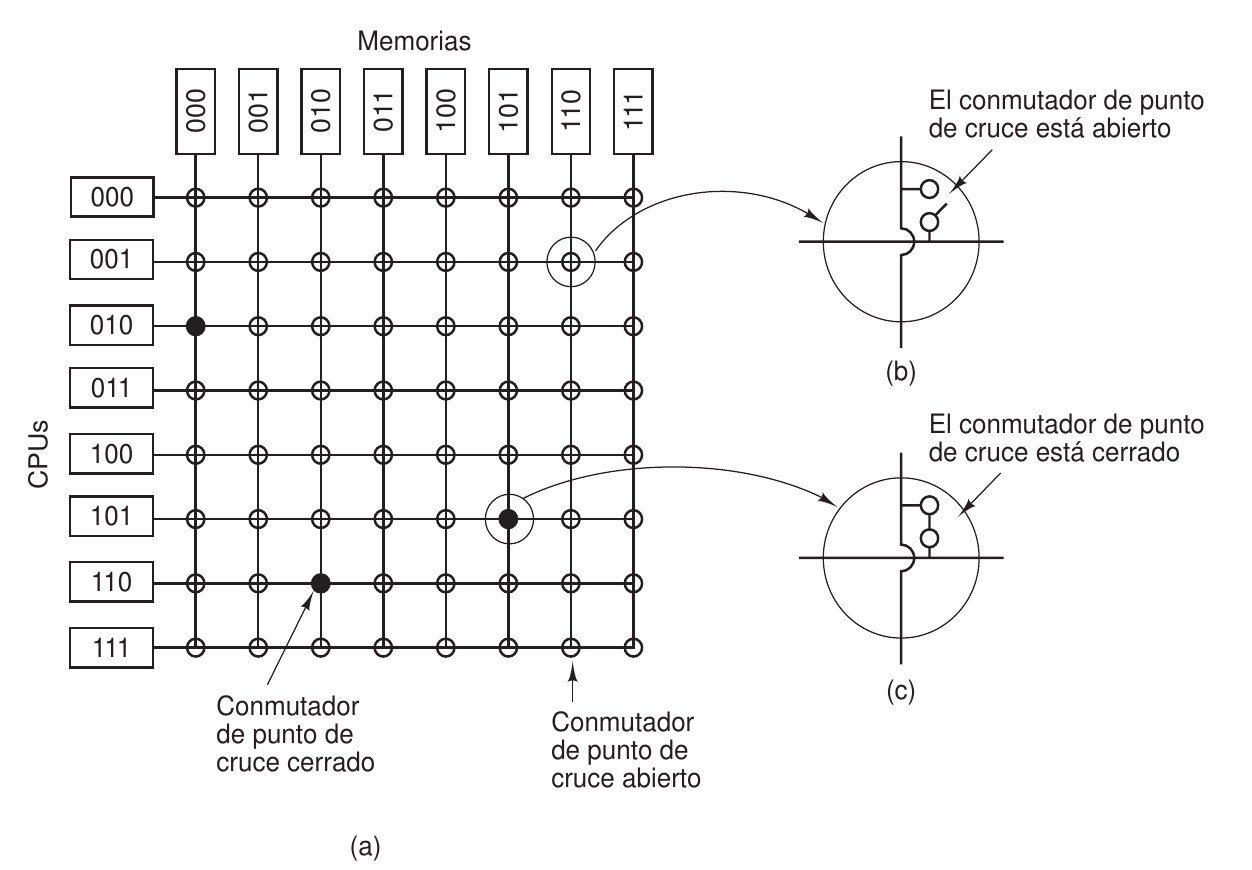
Conmutador de barras cruzadas
Aun así, un único bus sigue siendo bastante limitado si queremos escalar el número de CPUs. Para interconectar n CPUs a k memorias se puede utilizar un conmutador de barreras cruzadas (cross bar switch). La intersección de líneas verticales y horizontales se llama punto de cruze.
La ventaja de esto es que no hay bloqueos, solo si se intenta acceder a la misma memoria a la vez. El problema es que son dispositivos bastante costosos, y tampoco escala muy bien con más memorias y procesadores: cada vez será más grande.
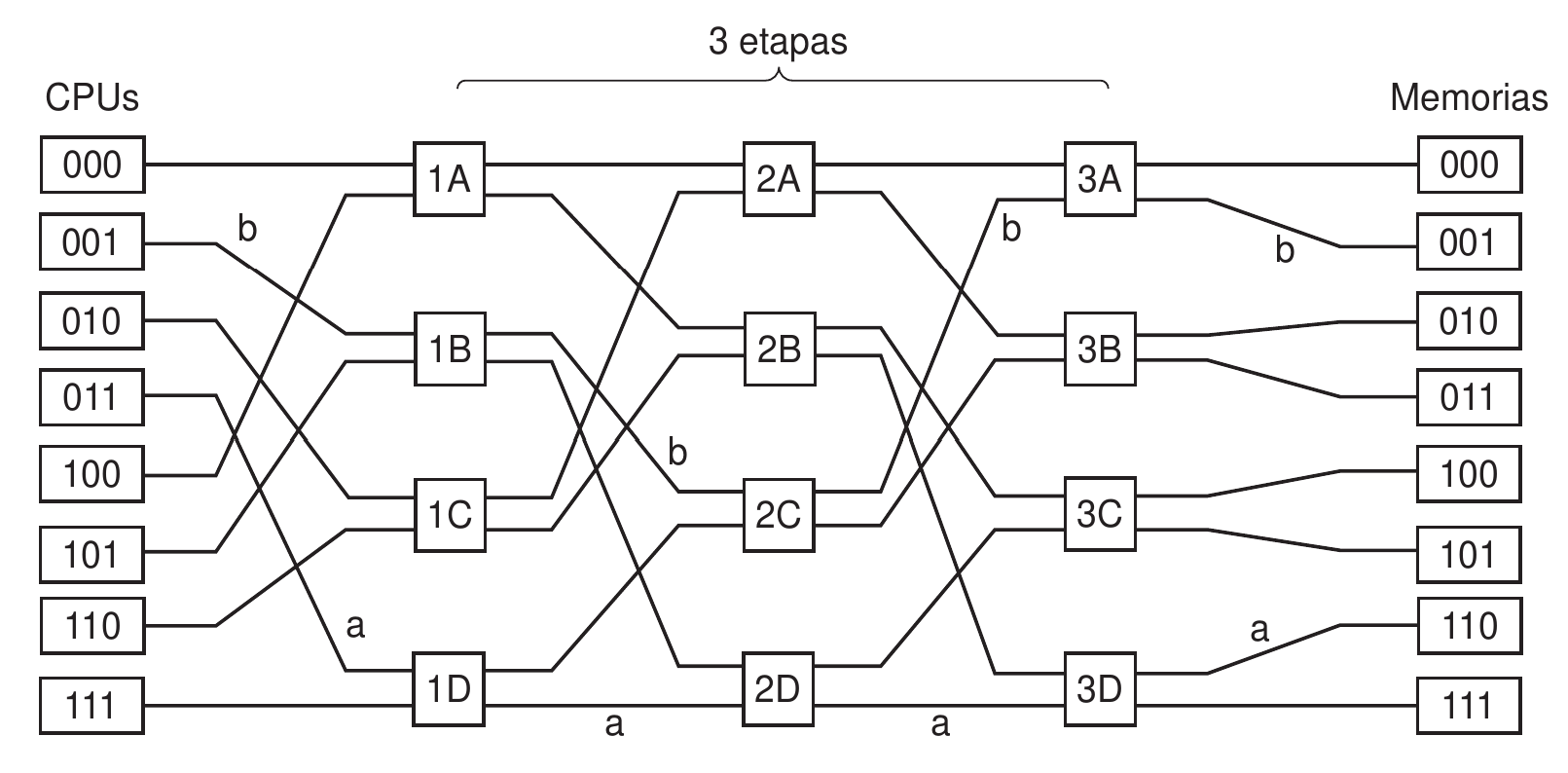
Red de conmutación omega de 3 etapas
Una posible alternativa intermedia es el uso de conmutadores: tiene dos entradas y dos salidas. Los mensajes llegan por una de las entradas y se pueden conmutar a cualquiera de las salidas, dependiendo de uns campos del parámetro recibido: el funcionamiento es muy similar a una red de routers de internet.
Estos conmutadores se pueden organizar en una red de comunicación multietapa, como por ejemplo la red omega de la figura. Esta red se conoce comúnmente como barajado perfecto (Perfect Shuffle): mezcla las señales como si fuese una barajas de cartas.
Estas resultan mucho más económicas que los conmutadores de barreras cruzadas, y ofrecen un mejor rendimiento que un único bus. Es cierto que todavía hay cierto nivel de contención (red con bloqueo), pero no tanta.
CC-NUMA (Cache Coherent NUMA)
Principios de multiprocesadores NUMA:
- Hay un solo espacio de direcciones visible para todas las CPUs.
- El acceso a la memoria remota es mediante simples
loadystore. - El acceso a la memoria remota es más lento que el acceso a la memoria local.
El sistema puede ser NC-NUMA (No Cache NUMA) o CC-NUMA (_Cache Coherent NUMA). En este apartado nos centraremos en este último.
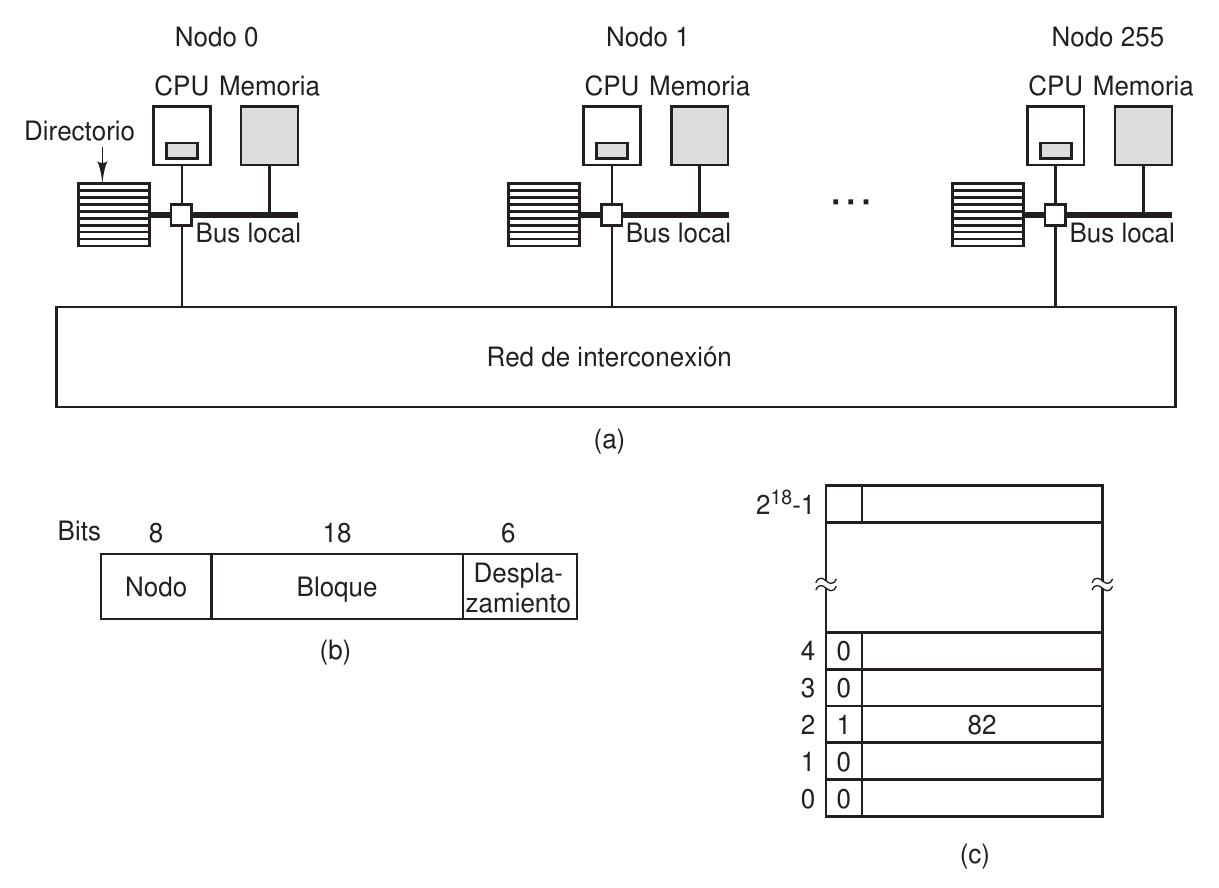
Sistema NUMA basado en directorio con 256 nodos
El método más utilizado en la actualidad es el multiprocesador basado en directorios: la idea es mantener como una base de datos de donde está cada línea caché y su estado (actualizada o modificada). Esto debe gestionarse en hardware dedicado que sea muy rápido.
Funcionamiento:
- La CPU que va a emitir la dirección debe pasar por la MMU.
- La MMU traduce la dirección.
- Luego, la divide en 3 partes: nodo, línea y desplazamiento.
- Si la solicitud es del nodo actual, se procede como siempre. Pero si es a un nodo de fuera, la MMU debe enviar un mensaje a través de la red de interconexión al nodo en concreto.
- Cuando llega a dicho nodo, se enruta al hardware del directorio. Este indexa en su tabla y extrae la línea correspondiente. Si no está en caché, se debe ir a la RAM del nodo.
- Se envía de vuelta la memoria necesaria a través de la red de interconexión.
Debido a todo esto, es muy importante la afinidad comentada antes para obtener un buen rendimiento.
Tipos de Sistemas Operativos Multiprocesador
Existen varias alternativas sobre el diseño de un Sistema Operativo que trabaje sobre una arquitectura multiprocesador:
| Cada CPU tiene su propio SO |
==> Poco popular. Se usó en los primeros sistemas multiprocesador para poder portar el SO lo más rápido posible. |
| Maestro-esclavo | El procesador maestro ejecuta el SO y reparte el trabajo entre otros procesadores. También es el encargado de gestionar las llamadas al sistema. ==> El procesador maestro para a ser el cuello de botella. |
| Simétricos (SMP) | Única copia del SO compartida por todas las CPUs
Otra ventaja es que hay una única tabla de procesos y una única tabla de páginas. Esta alternativa es más versátil y eficiente, lo que le da una mayor popularidad. Sin embargo, resulta mucho más complicado de implementar. |